

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 딥러닝
- 백준
- C++
- 강화학습
- LSTM
- eecs 498
- edge detection
- dynamic programming
- object detection
- opencv
- deep learning
- MySQL
- canny edge detection
- 그래프 이론
- 머신러닝
- two-stage detector
- One-Stage Detector
- YoLO
- AlexNet
- image processing
- machine learning
- Mask Processing
- MinHeap
- dfs
- CNN
- Reinforcement Learning
- DP
- Python
- BFS
- r-cnn
- Today
- Total
JINWOOJUNG
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection 본문
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
Jinu_01 2025. 2. 5. 01:55Papaer
Abstract
Sparse한 LiDAR PCD를 Region Proposal Network(RPN)과 연결하는 연구는 Hand-crafted Feature를 기반으로 연구되었다. 본 논문에서는 Feature Extraction과 Bounding Box Prediction을 하나의 Stage로 통합하여 E2E 학습이 가능한 Deep Network인 VexelNet을 제안한다. VoxelNet은 Point Cloud를 동일한 크기의 3D Voxel로 나눈 뒤, 각 Voxel 내 Point를 Voxel Feature Encoding(VFE) Layer를 통해 통합된 특징으로 표현한 결과를 RPN으로 전달하는 구조이다.
VoxelNet은 LiDAR Data만 활용하여 Car, Pedestrain, Cyclist 3D Object Detection에서 우수한 성능을 보인다.
Introduction
LiDAR PCD는 Depth 정보를 얻을 수 있지만, 이미지와 달리 매우 Sparse하고 Point Density가 가변적이다. 가려짐, 상대적 위치관계, 3D 공간의 비균일 샘플링 등으로 인해 Point Density가 균일하지 않고 가변적임을 확인할 수 있다.

Hand-craft Feature에서 벗어나 PointNet은 Point Cloud를 Input으로 하여 Point-wise Feature를 기반으로 한 E2E Deep Neural Network이다. PointNet은 Input을 특정 객체에 대해 Segemented Point Cloud 혹은 전체 Scene의 일부를 Input으로 가지기 때문에 Point Cloud의 개수가 적지만, 실제 LiDAR Sensor에서 얻어지는 PCD는 약 100,000개의 Point를 포함하기 때문에 그대로 처리하는 것은 높은 연산과 메모리를 요구한다. 본 논문에서는 대량의 PCD를 학습할 수 있도록 Network를 확장하고, 3D Object Detection을 Main Task로 한다.
RPN는 Image와 같이 Dense하고 Tensor 구조로 조직화 된 Data에 대해 효율적인 객체 탐지 알고리즘이지만, LiDAR PCD는 해당 특징을 만족하지 못한다. 본 논문에서는 Point Set Feature Learning과 RPN의 격차를 해소하는 방법을 제안한다.
VoxelNet Architecture
VoxelNet은 크게 3가지 구조로 나눌 수 있다.

Feature Learning Network
- Voxel Partition
LiDAR로 Scan한 PCD가 X,Y,Z 각 방향으로 W,H,D의 크기를 가진다고 하면, Voxel을 각 축에 대해 $v_W, v_H, v_D$의 크기로 설정하여 PCD를 3D Voxel로 나눈다. 이때, D,H,W는 $v_W, v_H, v_D$의 배수임을 가정한다. 따라서 생성된 3D Voxel Grid는 $W' = W/v_W, V' = V/v_V, D' = D/v_D$의 크기를 가진다.
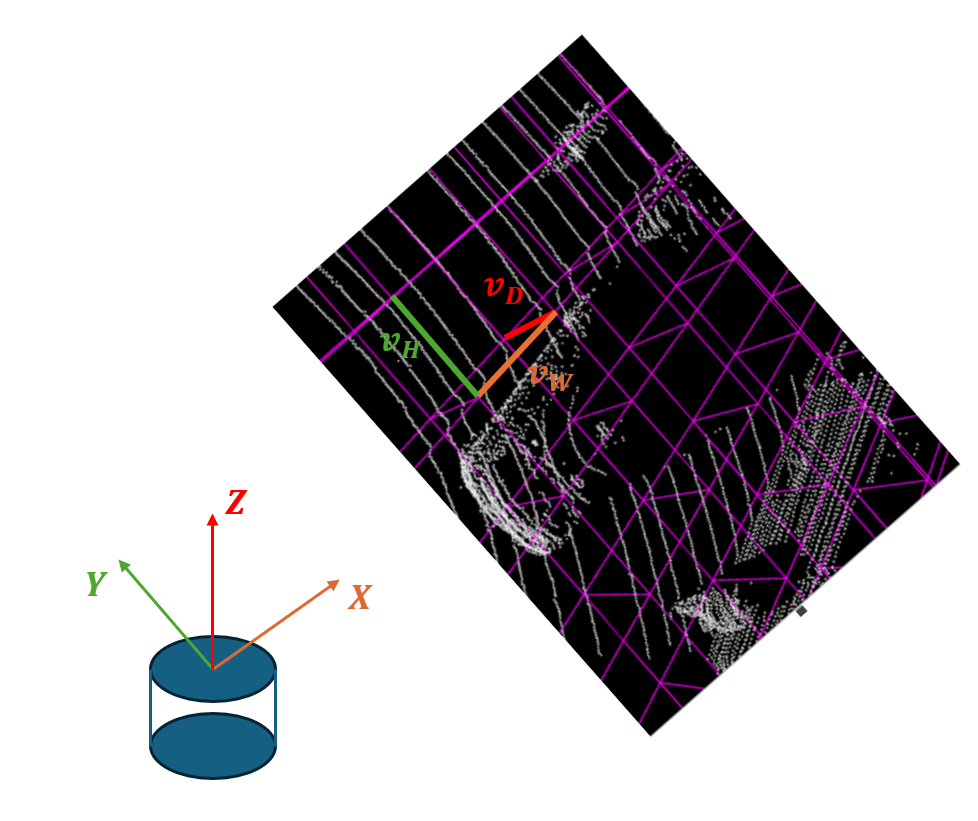

- Grouping
각 Voxel에 대해서 Grouping을 수행한다. 아래 Grouping 결과에서 볼 수 있듯이, LiDAR는 Sparse 하기 때문에 각 Voxel에 속하는 Point의 Density가 일정하지 않다.
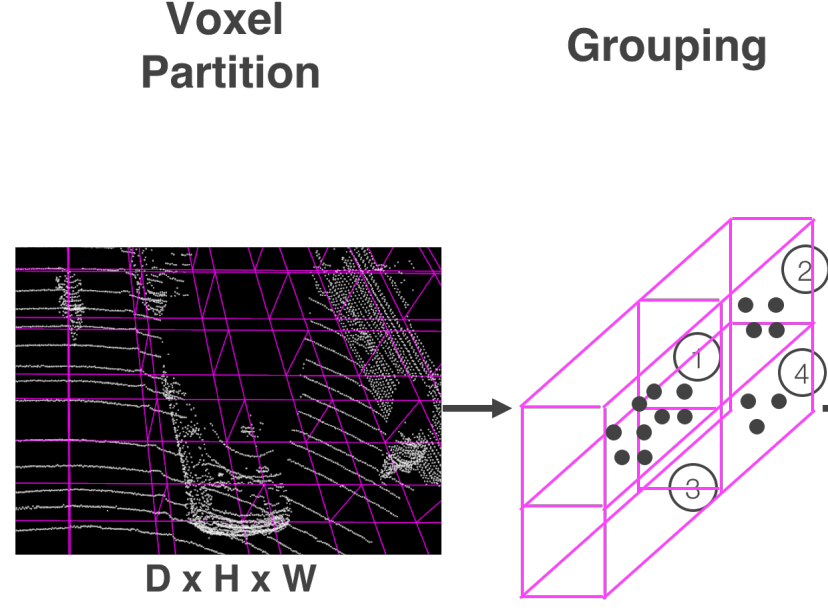
- Ramdom Sampling
각 Voxel 마다 Point Density도 다를 뿐만 아니라, LiDAR PCD는 약 100,000개의 Point로 구성되어 있기 때문에 바로 처리하면 큰 연산과 메모리가 요구되며 Density 차이에 의한 편향이 발생할 수 있다.
본 논문에서는 각 복셀이 가질 수 있는 최대 Point 개수를 $T$개로 설정하여, $T$개 이상의 Point가 속하는 경우 Random Sampling 한다. 이로인해 연산량을 줄이고, Voxel 간 Point 불균형을 감소시켜 Sampling 편향을 줄이고 일반화된 모델 학습을 가능하게 한다.
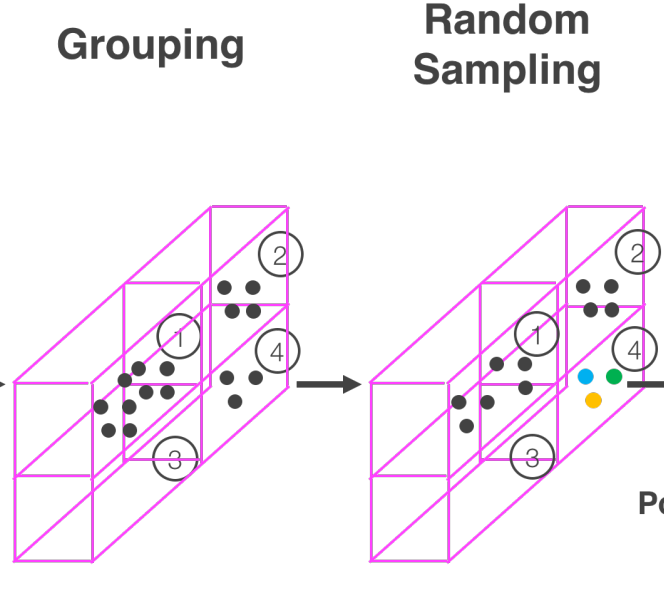
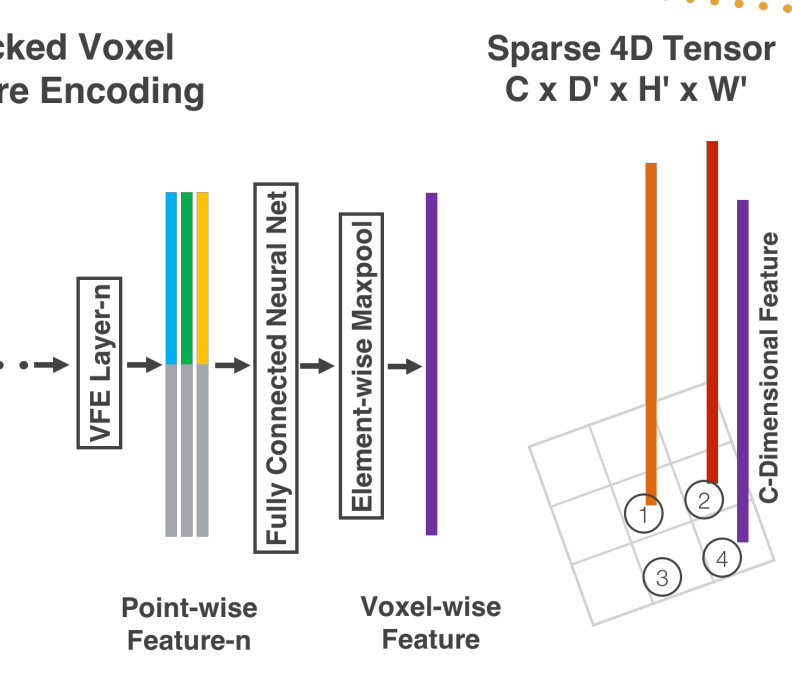
- Stacked Voxel Feature Encoding
아래 그림은 하나의 Voxel에 대해 계층적인 Feature Encoding 과정을 시각화 한 것이다.
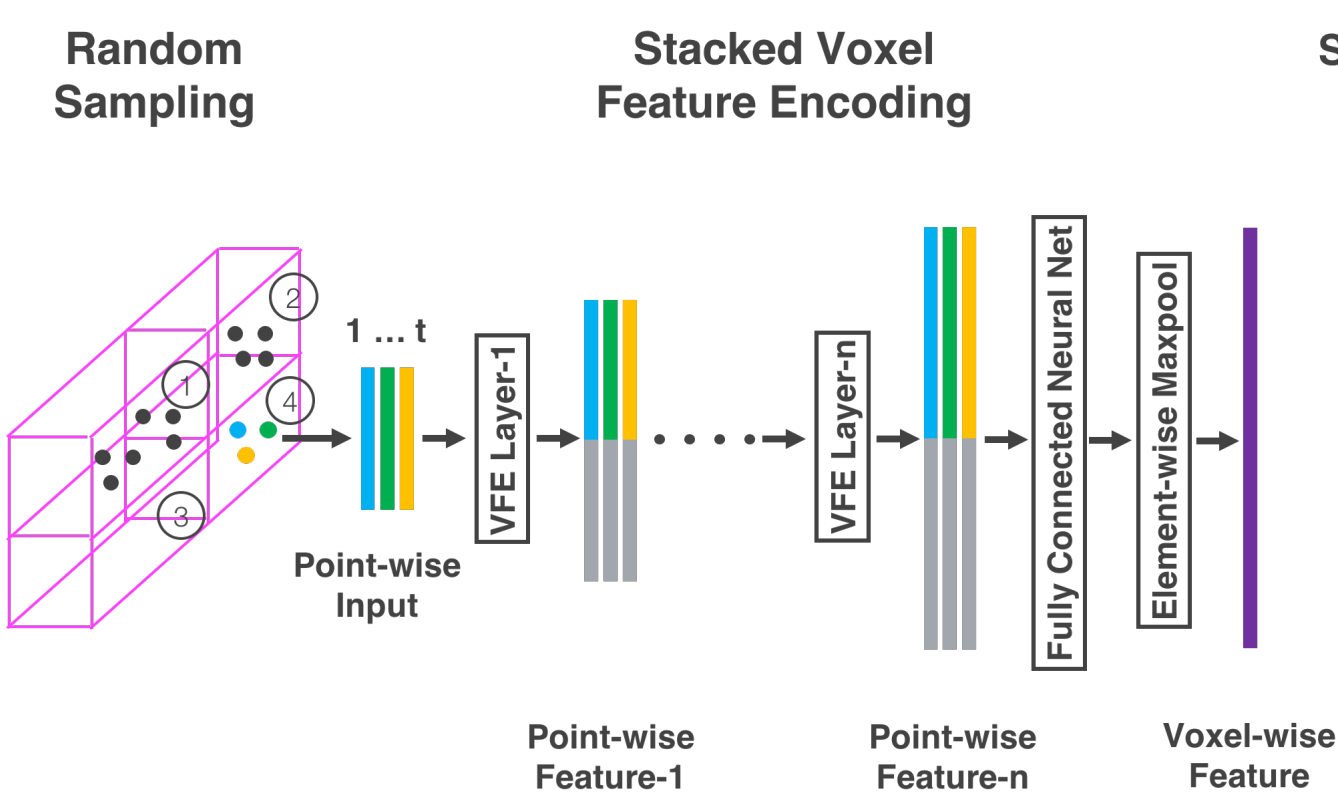
VFE Layer-1을 자세히 살펴보면 다음과 같다. 아래와 같이 비어있지 않은 $t$개의 Point를 포함하는 Voxel을 $V$라 할 때, $V$는 다음과 같이 정의된다.
$$ V = \left\{ p_i = [x_i, y_i, z_i, r_i]^T \in \mathbb{R}^4 \right\}_{i = 1\cdots t}$$
$V$는 $p_i$의 집합으로 표현되며, $p$는 각각의 Point의 $X,Y,Z$ 좌표 및 반사 강도(Reflectance) $r$을 포함한다. 이후, $V$에 포함되는 모든 Point의 중심 좌표인 $(v_x, v_y, v_z)$를 계산하여, 각각의 $V$에 $v$와 $p$의 Offset 즉, 각 Point가 Local Center와 떨어진 정도를 추가한다. 따라서 최종적인 Input Feature는 다음과 같다.
$$ V_{in} = \left\{ \hat{p}_i = [x_i, y_i, z_i, r_i, x_i - v_x, y_i - v_y, z_i - v_z]^T \in \mathbb{R}^7 \right\}_{i = 1\cdots t}$$
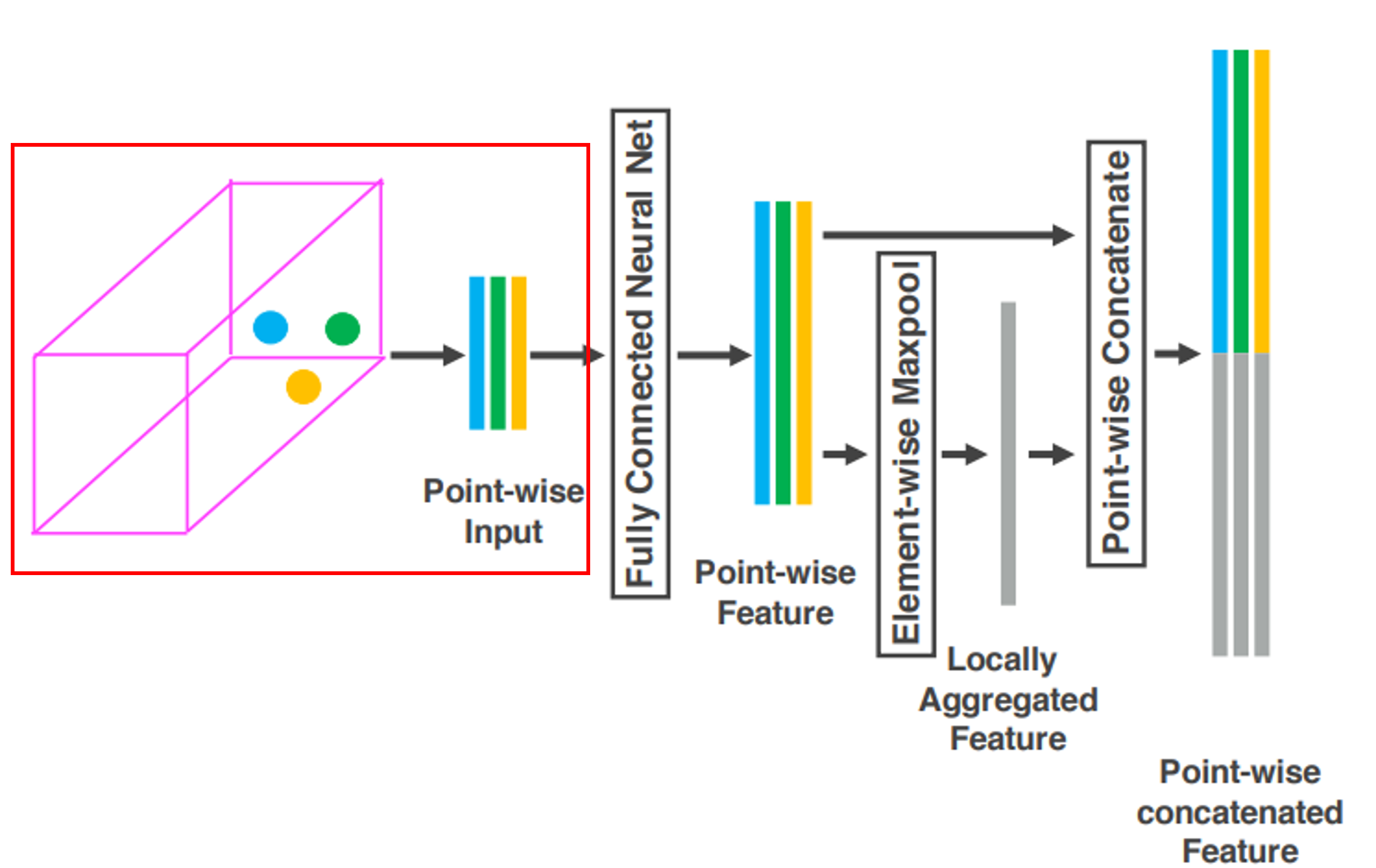
이후 각각의 $\hat{p}_i$는 Fully Connected Network(FCN)을 통해 Feature Space로 변환된다. 이 과정을 통해 Point Feature를 학습하여 Voxel 내부의 표면 형상을 인코딩 할 수 있다. 이때, FCN의 구조는 Linear Layer, Batch Normalization, ReLU로 구성된다.
Point들의 Feature 로부터 Voxel 내부의 표면 형상을 인코딩한다는 것이 무슨 의미일까?
$p_i$는 각 Point의 위치와 중심과의 상대적인 Offset 정보, 반사 강도를 포함한다. 따라서 객체의 표면을 따라 샘플링 된 Point 정보를 기반으로 FCN을 통해 각 포인트의 위치와 포인트간의 관계를 학습하여 개별 포인트의 구조적인 의미를 가진 $f_i$를 얻을 수 있다.
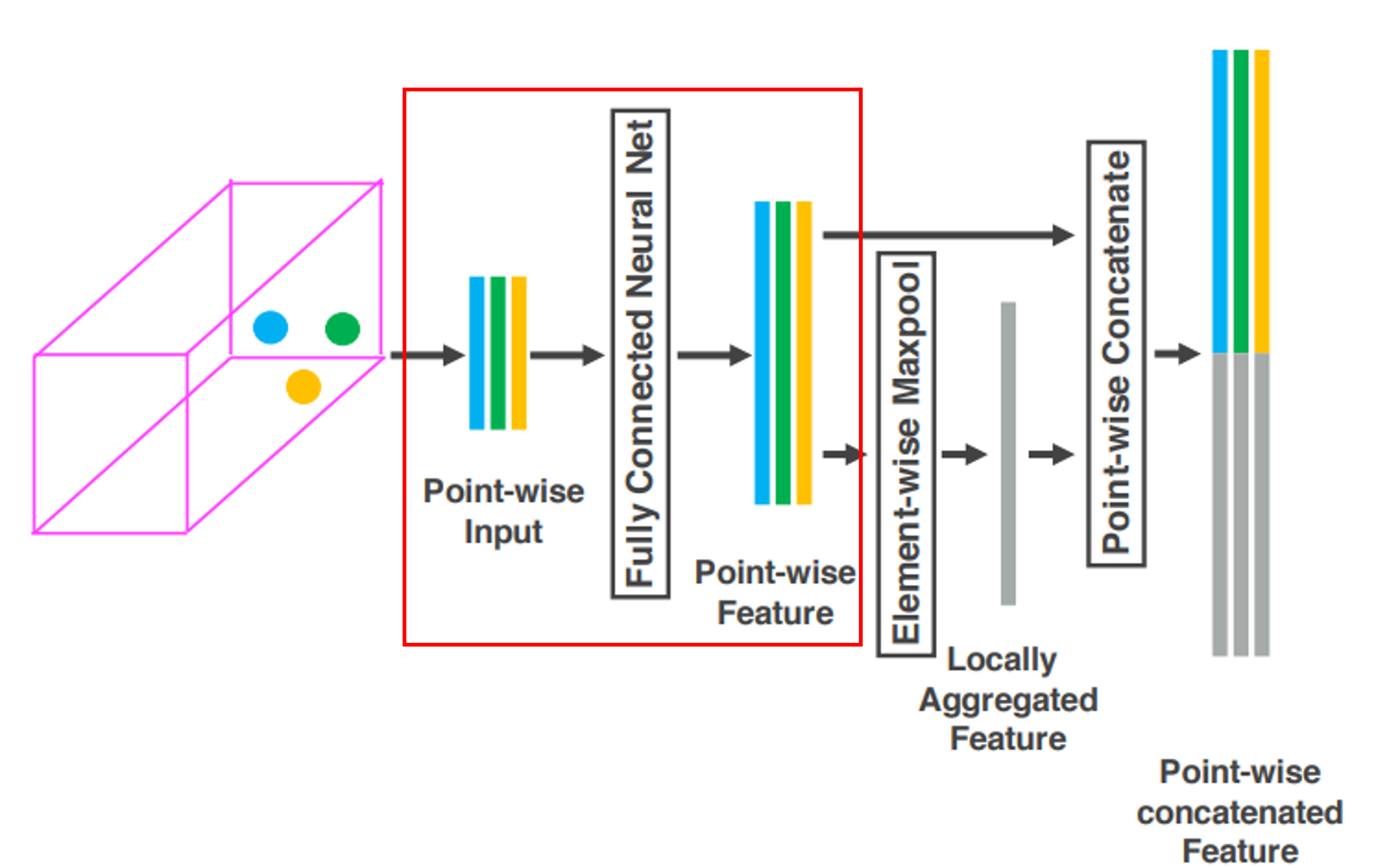
$\hat{p}_i \to f_i$로의 변환 이후, Voxel 내의 모든 Point에 대해 Element-wise Max Pooling을 통해 Local Feature $\widetilde{f}$를 얻는다(회색 막대). 최종적으로 각 Point의 특징 $f_i$와 Local Feature $\widetilde{f}$를 결합하여 최종적인 특징 $f_i^{out}$을 생성한다. 최종 출력 특징은 다음과 같다.
$$f_i^{out} = [f_i^T, $\widetilde{f}^T] \in \mathbb{R}^{2m}$$
$$V_{out} = \left\{ f_i^{out}\right\} _{i=1\cdots t} $$
Max Pooling 과정은 Voxel에 속하는 모든 Point의 Feature $f_i$ 중 가장 중요한 특징을 추출하여 해당 Voxel 내 Locally 의미있는 특징(Local Shape) $\widetilde{f}$을 얻을 수 있다.
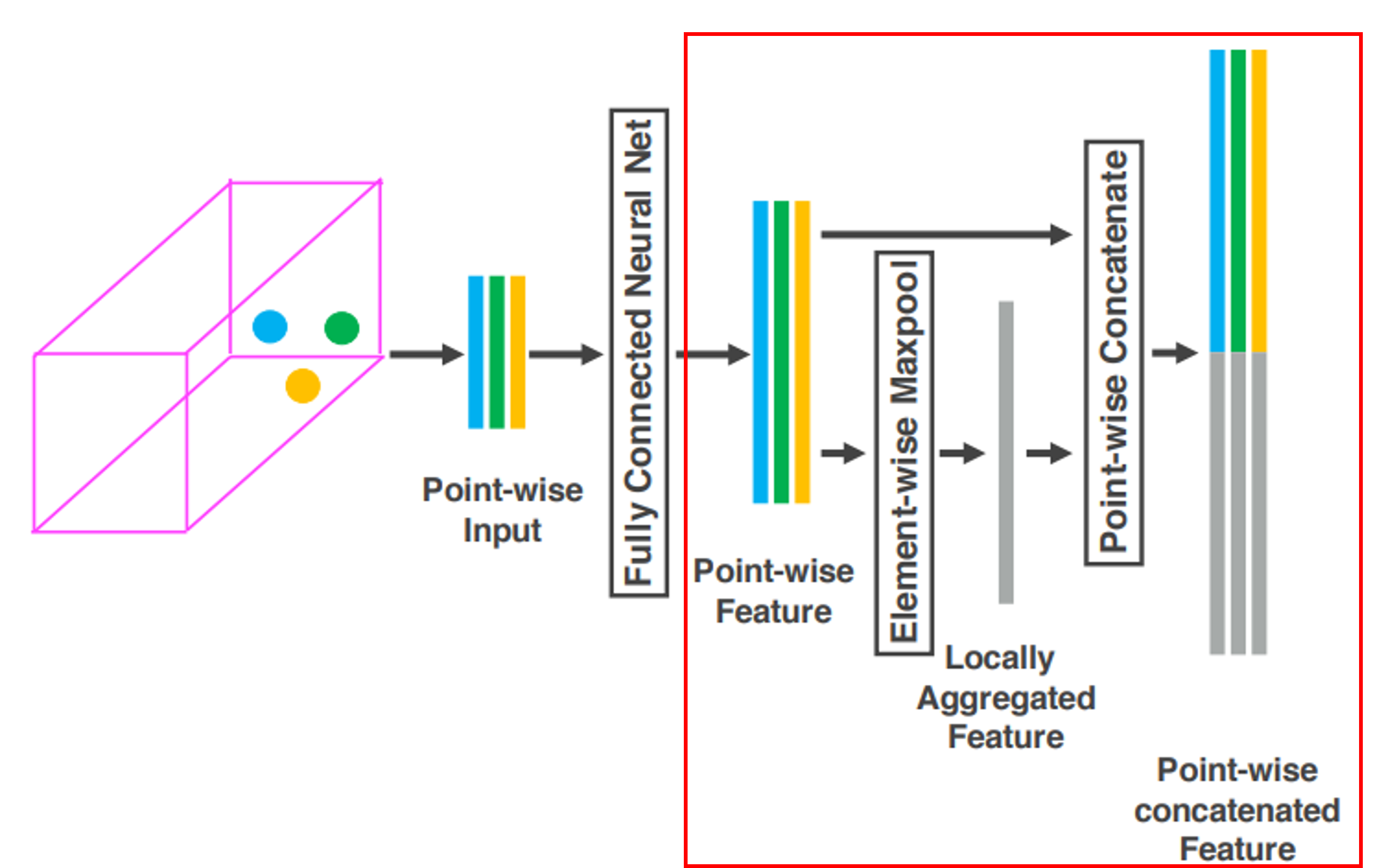
단순히 하나의 Layer가 아닌 여러 VFN을 쌓게 된다면, Voxel 내의 점 간 상호작용을 효과적으로 인코딩 할 수 있다. 이 과정을 통해 객체의 3D 형상을 정확하게 학습 가능하다.
마지막 VFE Layer인 VFN-n의 출력은 FCN을 통해 $\mathbb{R}^C$차원으로 변환된 후, Max Pooling을 통해 최종적인 Voxel-wise Feature를 생성한다.
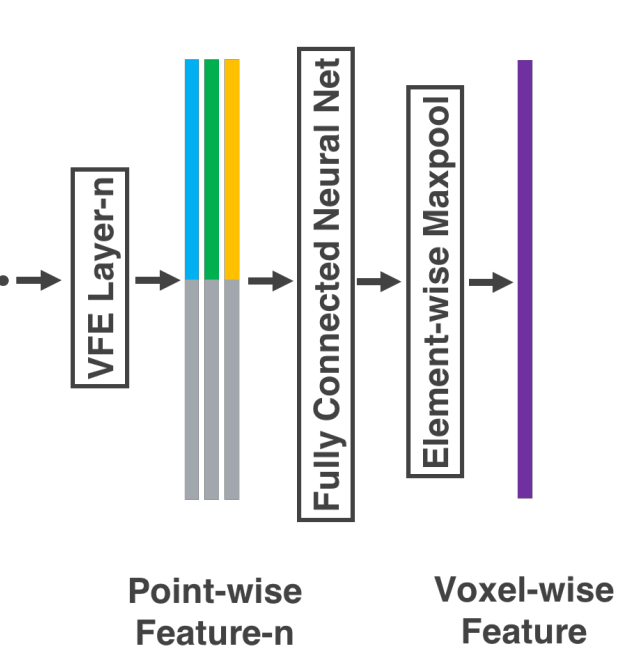
- Saprse Tensor Representation
VFN Layers를 거쳐 Voxel-wise Feature를 계산하는 과정은 비어 있지 않은 Voxel에 대해서만 처리하기 때문에, 각각의 Voxel에 대한 Voxel Feature List를 얻을 수 있다. 이는 Sparse한 LiDAR PCD의 특성을 반영하여 Sparse 4D Tensor로 표현되며, 메모리 사용량을 줄이고, Backpropagation 과정에서 연산 비용을 줄일 수 있다.
Convolutional Middle Layers
VFE Layers를 통해 Voxel-wise Feature를 Sparse 4D Tensor 형태로 얻었다. 이는 각 Voxel의 특징을 계산하여 Tensor 형태로 표현한 형태이다.
Convolutional Middle Layers는 3D Convolution, Batch Normalization(BN), ReLU로 구성되어 있으며, 레이어를 거치면서 Receptive Field가 확장된다. 이를 통해 각 Voxel 간의 관계를 학습하며, 3D 공간에서 연속적인 Shape 정보를 점진적으로 반영할 수 있도록 한다. 즉, 개별 Voxel이 아니라, 인접한 Voxel들과 함께 처리되면서 전체적인 3D 구조를 학습할 수 있도록 한다.
본 논문에서는 $ConvMD(C_{in}, c_{out}, k, s, p)$를 $M$차원 Convolution Operator로 정의한다. 이때, $c_{in}, c_{out}$은 입, 출력 체널 수, $k,s,p$는 Kernel Size, Stride Size, Padding Size를 나타내는 $M$ 차원 Vector이다.
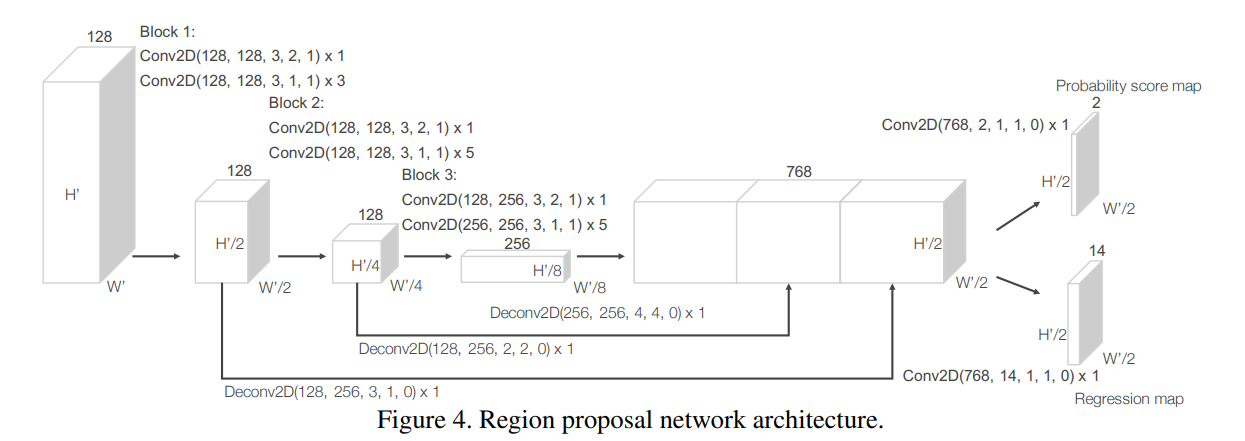
Region Proposal Network
RPN의 Input은 Convolutional Middel Layers의 Output Feature Map이다.
RPN은 3개의 Fully Convolutional Blocks로 이루어져 있으며, 각 Block의 첫번째 Convolution은 Stride가 2로 Downsampling되며, 이후 Stride가 1인 Convolution을 여러번 적용하여 특징을 정제한다. 각 Block의 처리 이후 Batch Noramalization과 ReLU를 적용한다.
따라서 각각의 Block은 서로 다른 Receptive Feild를 가지는 Feature Map을 생성하게 된다. 따라서 각각의 Feature Map의 크기를 동일하게 Upsampling 한 뒤, 연결하여 고해상도의 Feautre Map을 생성하게 된다. 즉, 서로 다른 크기의 객체를 검출하기 위한 정보를 얻을 수 있다.
최종적인 Feature Map은 객체가 존재할 가능성인 Probability Score Map, 3D BBox를 조정하는 Regression Map을 예측함으로써 3D 객체 검출을 위한 Region Proposal Network가 동작하게 된다.
Loss Function
$\left\{ a_i^{pos} \right\}_{i=1}^{N_{pos}}$는 $N_{pos}$개의 Positive Anchor Set, $\left\{ a_j^{neg} \right\}_{j=1}^{N_{neg}}$는 $N_{neg}$개의 Negative Anchor Set라 하자.
Ground Truth는 $(x_c^g, y_c^g, z_c^g, l^g, w^g, h^g, \theta^g)$, Positive Anchor $a_i^{pos}$는 $(x_c^a, y_c^a, z_c^a, l^a, w^a, h^a, \theta^a)$라 하자. 이때, $ x_c^g, y_c^g, z_c^g$는 3D Bounding Box의 중심점, $ l^g, w^g, h^g$는 Bounding Box의 길이, 너비, 높이, $\theta^g$는 Z축을 중심으로 한 Yaw 회전각(Heading)을 의미한다.
본 논문에서는 Positive Anchor를 GT로 대응시키기 위한 7차원의 정답 잔차 벡터(Residual Vector) $u^*$을 다음과 같이 정의한다.
$$u^* = \left [ \Delta x, \Delta y, \Delta z, \Delta l, \Delta w, \Delta h, \Delta \theta \right ]$$
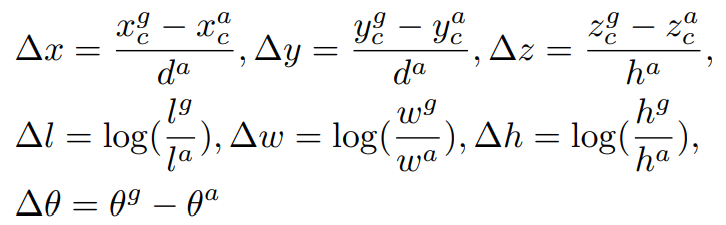
이때, $d^a = \sqrt{(l^a)^2 + (w^a)^2}$로 계산되며 이는 Anchor Box의 바닥 대각선을 의미한다. 본 논문에서는 Oriented 3D Box를 직접 예측하며, $ \Delta x, \Delta y$를 $d^a$로 정규화 하는 점이 차별점이다.
이를 바탕으로 Loss Function $L$은 다음과 같이 정의된다.
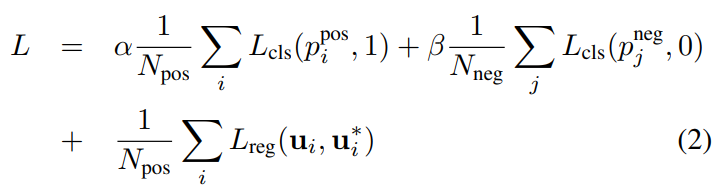
이때, $p$는 각 Anchor에 대한 Softmax Output이며, $u_i$는 Model의 예측 값이다.
$L$의 처음 2개의 Term은 Normalized Classification Loss이며, $L_{cls}$는 Binary Cross-entropy Loss이고, $\alpha, \beta$는 Positive, Negative의 Balance를 위한 Hyperparameter이다. 마지막 Term은 Regression Loss로 SmoothL1 Function을 사용한다.
Network Details
VoxelNet은 Car, Pedestrian, Cyclist 총 3개의 Class에 대한 3D Object Detection을 수행한다. 각각의 Class를 검출 할 때 앞서 정의한 Network 구조 및 Hyperparameter가 다르므로 논문을 참고하기 바란다.
Experiment
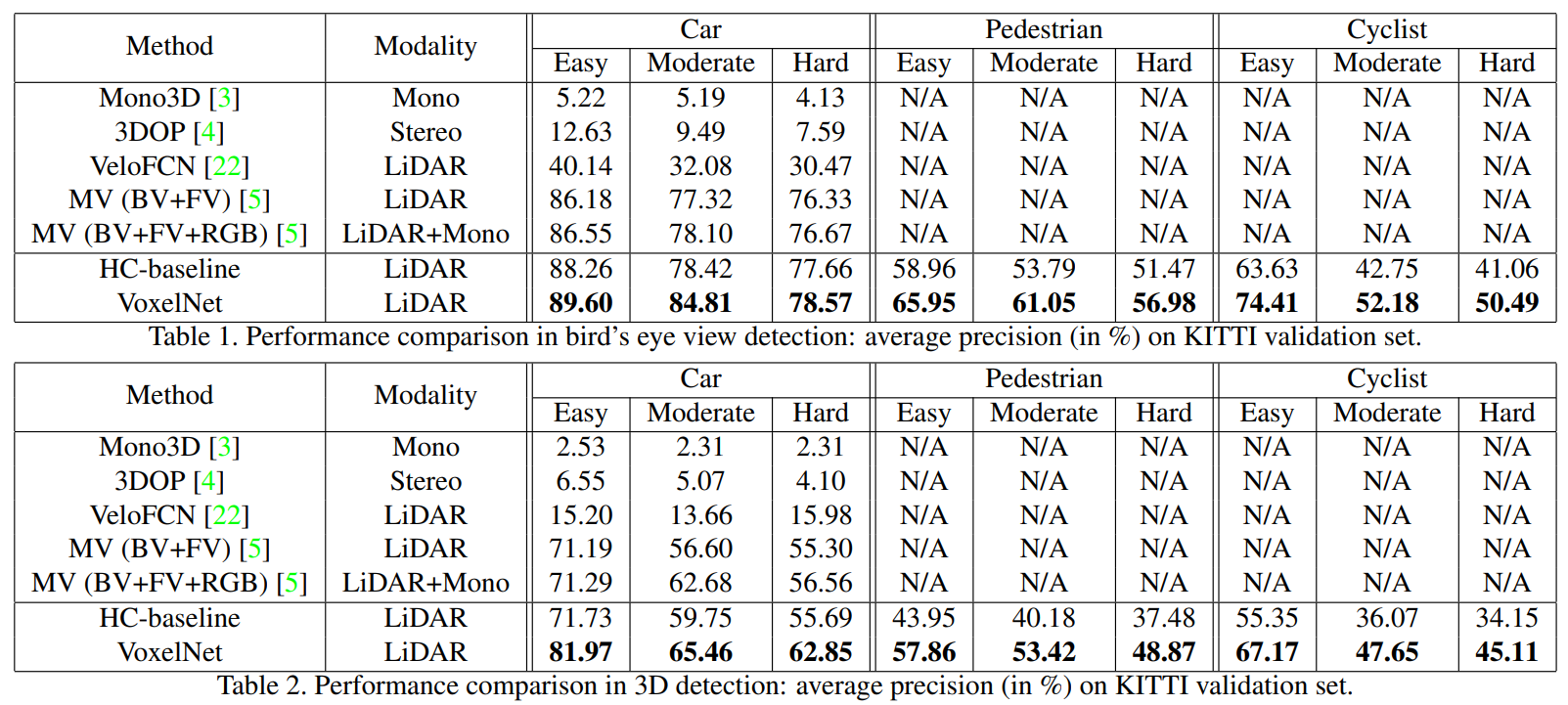
LiDAR 3D Data를 위에서 아래로 본 관점인 2D 평면으로 변환한 Bird's Eye View에서의 Detection과 3D Detection 모두 우수한 성능을 보임. 이때, HC-baseline은 VoxelNet 구조에서 Hand-craft Feature를 사용한 방법으로, VoxelNet을 통해 E2E로 학습하여 훨신 뛰어난 성능을 보일 수 있음을 증명한다.
'딥러닝 > 논문' 카테고리의 다른 글
| PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation (0) | 2025.02.03 |
|---|---|
| Focal Loss for Dense Object Detection(RetinaNet) (0) | 2025.01.22 |
| SSD: Single Shot MultiBox Detector (0) | 2025.01.20 |
| You Only Look Once: Unified, Real-Time Object Detection(YOLO) (0) | 2025.01.19 |
| Fast R-CNN...(2) (0) | 2025.01.12 |


