
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- deep learning
- opencv
- MySQL
- ubuntu
- Reinforcement Learning
- Python
- NLP
- DP
- One-Stage Detector
- 딥러닝
- BFS
- CNN
- image processing
- 머신러닝
- dynamic programming
- two-stage detector
- C++
- 그래프 이론
- eecs 498
- r-cnn
- dfs
- MinHeap
- Mask Processing
- 백준
- machine learning
- 강화학습
- real-time object detection
- YoLO
- LSTM
- AlexNet
- Today
- Total
JINWOOJUNG
[ DB ] 데이터베이스...6(SQL...2) 본문
본 포스팅은 인하대학교 최원익교수님의 "데이터베이스설계" 수업에서 진행한 프론트, 백엔드 실습 관련 정리하는 포스팅입니다. 백엔드, 프론트엔드는 전문 분야가 아니기에 공부용으로 올리는 포스팅이며 오류사항이 있을 수 있습니다.
https://jinwoo-jung.tistory.com/104
[ DB ] 데이터베이스...5(SQL...1)
본 포스팅은 인하대학교 최원익교수님의 "데이터베이스설계" 수업에서 진행한 프론트, 백엔드 실습 관련 정리하는 포스팅입니다. 백엔드, 프론트엔드는 전문 분야가 아니기에 공부용으로 올리
jinwoo-jung.com
이전 포스팅에서 생성한 Database를 기반으로 진행합니다.
- SELECT - FROM - WHERE
SELECT문의 구조는 다음과 같다.
SELECT <AttributeList>
FROM <TableList>
WHERE <Condition>
<AttributeList>는 질의 결과에 나타나는 Attribute List이다.
<TableList>는 질의 대상이 되는 Relation List이다.
<Condition>은 질의 결과의 Tuples가 충족해야 하는 조건식이다.
새로운 Table을 만들어 활용방법을 살펴보자. Table t1, t2를 생성하자.

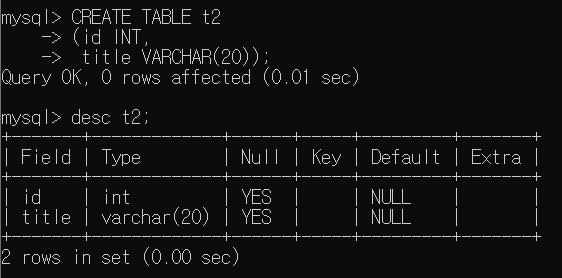
SELECT문을 살펴보는 목적이기에, 추가적인 제약조건 등은 설정하지 않았다. 몇개의 Tuples를 입력한 결과 다음과 같다.


SELECT * FROM TABLE이름; 은 해당 Table의 모든 Tuples를 반환한다.
- Select * from t1, t2 where t1.id = t2.id
조건문을 먼저 살펴보면 t1.id = t2.id 로, t1 Table의 id와 t2 Table의 id가 같은 Tuple들에 대하여, t1, t2 Table의 모든 Column을 출력하라는 의미이다.
이 방법이 Equi Join이다.

Join 연산
Join 연산은 두 Table을 결합시키는 연산이다.
Join 연산은 크게 3가지로 Cross Join, Inner Join, Outer Join으로 나뉜다. 그리고, Inner Join에는 Equi Join, Natural Join이 있으며, Outer Join에는 Left Join, Right Join이 있다.
Cross Join
- Select * from t1 cross join t2
두 테이블 사이에 모든 가능한 조합을 반환한다.
(t1, t2 Table은 Tuple을 더 추가해서 t4, t5 Table 사용.)
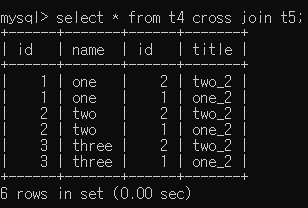
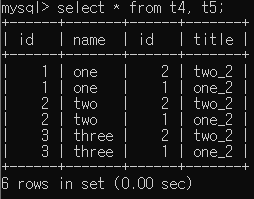
이는 select * from t1, t2; 에서도 동일한 결과가 나옴을 확인할 수 있습니다.
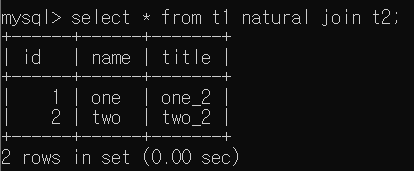
- Select * from t1 natural join t2
natural join의 경우 두 테이블이 갖는 공통 Column에 대하여 같은 값을 갖는 Column을 하나의 Column으로 나타낸다. 만약 같은 값을 가지는게 없으면 제외된다.
SELECT 구조에서 <TableList>에 Join연산이 포함된다. 따라서 t1 natural join t2가 하나의 새로운 table이라고 생각하면 아래 결과가 자연스럽게 나올 것이다.
Select * from t1, t2 where t1.id = t2.id 는 id Attribute가 2번 나오지만, natural join의 경우 하나의 Column으로 나타나는 차이가 있다.
만약, 같은 값이 없는 경우는 Empty를 반환한다.
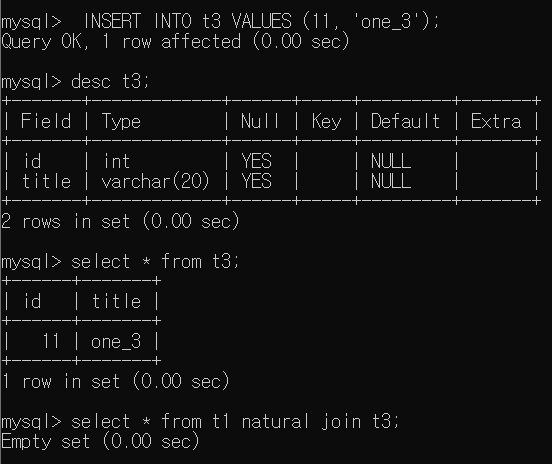
t1 Table에 id = 4, name = 'four'인 Tuple을 하나 더 추가한 뒤 진행하자.
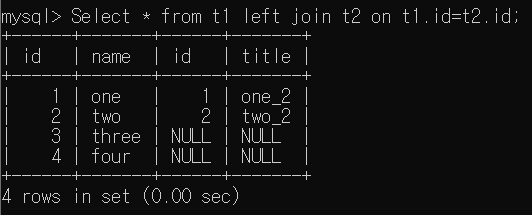
- Select * from t1 left join t2 on t1.id=t2.id
LEFT JOIN은 왼쪽 Table의 모든 행을 반환하고, 오른쪽 Table에서 일치하는 행이 있는 경우는 해당 데이터를 가져오고 없으면 Null을 가져오는 Join 연산이다.
아래 오른쪽 결과와 같이, t1 Table의 모든 행이 반환되었으며, t1.id = t2.id인 경우, t2 Table의 데이터가 가져와지고, 아니면 NULL이 채워짐을 확인할 수 있습니다.

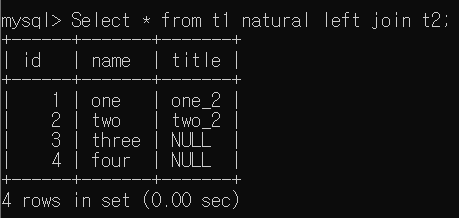
- Select * from t1 natural left join t2
위 결과에서는 중복되는 id Column이 모두 나타난다. 그렇다면 중복되는 것을 하나만 표현하려면 앞서 설명한 Natural을 활용하면 된다.
중복되는 id Column은 하나만 표현되었으며, left join이기에 같은 값을 가지지 않는 id 3, 4에 대한 title의 경우 NULL이 나타남을 확인할 수 있습니다.
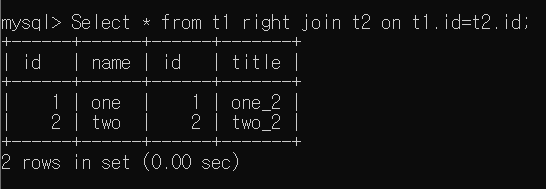
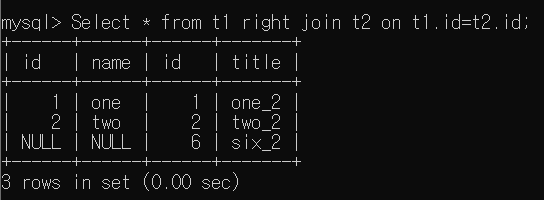
- Select * from t1 right join t2 on t1.id=t2.id
RIGHT JOIN은 오른쪽 Table의 모든 행을 반환하고, 왼쪽 Table에서 일치하는 행이 있는 경우는 해당 데이터를 가져오고 없으면 Null을 가져오는 Join 연산이다. 주가 되는 Table이 LEFT JOIN과 반대로 오른쪽인 것만 차이가 있다.
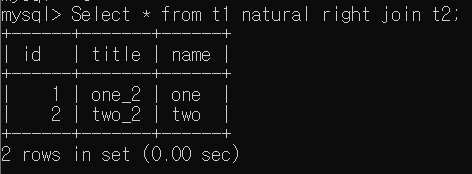
- Select * from t1 natural right join t2
앞선 결과와 중복되는 id Column이 사라지는 것 외 동일한 결과가 나타난다.
- Select * from t1 right join t2 on t1.id=t2.id;
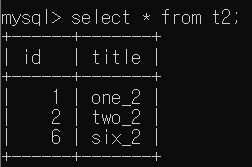
그렇다면, t2 Table에 t1에 없는 id를 가진 tuple을 추가해서 동일한 연산을 해 보자 . right join은 오른쪽 Table을 다 가져오고, 중복되는 행이 있으면 해당 데이터를 가져오고 없으면 NULL이므로 id 6에 대한 t2 Table의 id, name Value는 모두 NULL이 될 것이다.
'Database' 카테고리의 다른 글
| [ DB ] 데이터베이스...8(SQL...4) (0) | 2024.10.12 |
|---|---|
| [ DB ] 데이터베이스...7(SQL...3) (0) | 2024.10.12 |
| [ DB ] 데이터베이스...5(SQL...1) (2) | 2024.10.11 |
| [ DB ] 데이터베이스...4(MySQL) - 작성중 (0) | 2024.10.11 |
| [ DB ] 데이터베이스...3(EER Diagram) (0) | 2024.09.30 |


