
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 딥러닝
- dfs
- 머신러닝
- Mask Processing
- CNN
- YoLO
- machine learning
- LSTM
- 강화학습
- DP
- 그래프 이론
- two-stage detector
- MinHeap
- Python
- One-Stage Detector
- r-cnn
- deep learning
- real-time object detection
- image processing
- C++
- opencv
- 백준
- object detection
- MySQL
- ubuntu
- dynamic programming
- AlexNet
- eecs 498
- BFS
- Reinforcement Learning
- Today
- Total
JINWOOJUNG
[EECS 498] Assignment 2. Two Layer Neural Network...(2) 본문
[EECS 498] Assignment 2. Two Layer Neural Network...(2)
Jinu_01 2024. 12. 30. 00:50본 포스팅은 Michigan Univ.의 EECS 498 강의를 수강하면서 공부한 내용을 정리하는 포스팅입니다.
https://jinwoo-jung.tistory.com/126
[EECS 498] Assignment 2. Two Layer Neural Network...(1)
본 포스팅은 Michigan Univ.의 EECS 498 강의를 수강하면서 공부한 내용을 정리하는 포스팅입니다.https://jinwoo-jung.tistory.com/125 [EECS 498] Assignment 2. Linear Classifier...(2)본 포스팅은 Michigan Univ.의 EECS 498 강
jinwoo-jung.com
Train Neural Network using CIFAR-10
- Train with default parameters
import eecs598
# Invoke the above function to get our data.
eecs598.reset_seed(0)
data_dict = eecs598.data.preprocess_cifar10(dtype=torch.float64)
print('Train data shape: ', data_dict['X_train'].shape)
print('Train labels shape: ', data_dict['y_train'].shape)
print('Validation data shape: ', data_dict['X_val'].shape)
print('Validation labels shape: ', data_dict['y_val'].shape)
print('Test data shape: ', data_dict['X_test'].shape)
print('Test labels shape: ', data_dict['y_test'].shape)
# Train data shape: torch.Size([40000, 3072])
# Train labels shape: torch.Size([40000])
# Validation data shape: torch.Size([10000, 3072])
# Validation labels shape: torch.Size([10000])
# Test data shape: torch.Size([10000, 3072])
# Test labels shape: torch.Size([10000])
CIFAR-10 Dataset은 3x32x32 Shape를 가지고 10개의 클래스로 구성된 이미지 데이터셋이다.
Dataset은 data_dict에 Dictionary 형태로 저장되어 있으며 Train 40,000개, Validation 10,000개, Test 10,000개로 구성되어 있다.
import eecs598
from two_layer_net import TwoLayerNet
input_size = 3 * 32 * 32
hidden_size = 36
num_classes = 10
# fix random seed before we generate a set of parameters
eecs598.reset_seed(0)
net = TwoLayerNet(input_size, hidden_size, num_classes, dtype=data_dict['X_train'].dtype, device=data_dict['X_train'].device)
# Train the network
stats = net.train(data_dict['X_train'], data_dict['y_train'],
data_dict['X_val'], data_dict['y_val'],
num_iters=500, batch_size=1000,
learning_rate=1e-2, learning_rate_decay=0.95,
reg=0.25, verbose=True)
# Predict on the validation set
y_val_pred = net.predict(data_dict['X_val'])
val_acc = 100.0 * (y_val_pred == data_dict['y_val']).double().mean().item()
print('Validation accuracy: %.2f%%' % val_acc)
가장 기본적인 Hyperparameter를 기반으로 Model을 학습시켜 Validation에 대한 Accuracy를 측정한 결과 9.77%로 매우 낮은 성능을 보임을 확인할 수 있다.
- Debug the training
모델의 부정확한 학습 결과를 분석하기 위한 방법은 크게 2가지가 있다.
- Visualization loss function and accuracy graph
Loss history를 살펴보면, 초기 Loss는 약 2.3으로 초기 모델에서 나올 수 있는 값이다. 이후 전체적으로 Loss가 감소하고 있지만, 약 200 Epoch 이후로부터는 Loss의 감소가 거의 없고 진동하는 모습을 보인다. 또한, Loss가 감소하는 과정이 거의 선형적으로 감소하는 것을 확인할 수 있는데, 이는 학습이 느리게 진행됨을 암시한다.
Accuracy의 경우 증가하는 그래프가 아닌 일관되게 낮은 범위에 머무르는 것을 확인할 수 있으며, 진동하는 것으로 보아 모델이 학습을 잘 못하고 있는 것으로 확인된다. 이는 모델이 복잡한 패턴을 학습하지 못하고 Underfitting 됨을 암시한다.

- Visualization weight of first layer
Network의 첫번째 Layer의 Weight Matrix는 Edge나 Corner등 시각적인 특징이 예상되나, 아래 Weight를 시각화 한 경우 무작위적인 패턴처럼 보인다. 이는 모델이 데이터를 제데로 학습하지 못함을 의미한다.

- Select Hyperparameter
학습 결과를 디버깅 한 것을 바탕으로, 네트워크의 Hyperparameter를 변경시켜 모델의 Accuracy를 증가시켜 보자.
- Capacity
Capacity는 모델의 용량 즉, 신경망이 데이터의 복잡한 패턴을 학습할 수 있는 능력(표현력)이다. 모델의 Capacity가 충분하지 않으면 데이터의 복잡한 구조를 학습할 수 없어 Underfitting이 발생할 수 있다.
앞선 Default parameter에서는 capacity를 36으로 하였지만, 모델의 Accuracy가 낮고, 모델의 복잡성이 부족해 데이터를 잘 표현하지 못함을 확인하였다.
import eecs598
from eecs598.a2_helpers import plot_acc_curves
from two_layer_net import TwoLayerNet
hidden_sizes = [2, 8, 32, 128]
lr = 0.1
reg = 0.001
stat_dict = {}
for hs in hidden_sizes:
print('train with hidden size: {}'.format(hs))
# fix random seed before we generate a set of parameters
eecs598.reset_seed(0)
net = TwoLayerNet(3 * 32 * 32, hs, 10, device=data_dict['X_train'].device, dtype=data_dict['X_train'].dtype)
stats = net.train(data_dict['X_train'], data_dict['y_train'], data_dict['X_val'], data_dict['y_val'],
num_iters=3000, batch_size=1000,
learning_rate=lr, learning_rate_decay=0.95,
reg=reg, verbose=False)
stat_dict[hs] = stats
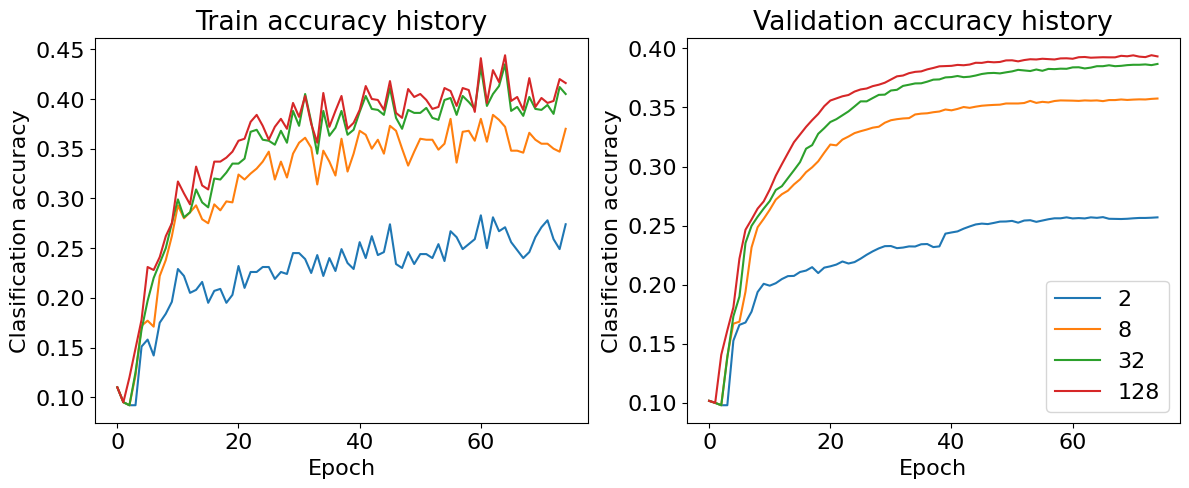
plot_acc_curves(stat_dict)
다른 Parameter는 고정시킨 뒤, Capacity만 조절하여 학습시킨 결과 Capacity가 증가할수록 모델이 데이터의 복잡성을 잘 학습하고 Accuracy 역시 증가함을 확인할 수 있다.
- Regularization
Regularization 계수가 너무 높으면 모델이 훈련 데이터를 제데로 학습하지 못할 수 있다.
import eecs598
from eecs598.a2_helpers import plot_acc_curves
from two_layer_net import TwoLayerNet
hs = 128
lr = 1.0
regs = [0, 1e-5, 1e-3, 1e-1]
stat_dict = {}
for reg in regs:
print('train with regularization: {}'.format(reg))
# fix random seed before we generate a set of parameters
eecs598.reset_seed(0)
net = TwoLayerNet(3 * 32 * 32, hs, 10, device=data_dict['X_train'].device, dtype=data_dict['X_train'].dtype)
stats = net.train(data_dict['X_train'], data_dict['y_train'], data_dict['X_val'], data_dict['y_val'],
num_iters=3000, batch_size=1000,
learning_rate=lr, learning_rate_decay=0.95,
reg=reg, verbose=False)
stat_dict[reg] = stats
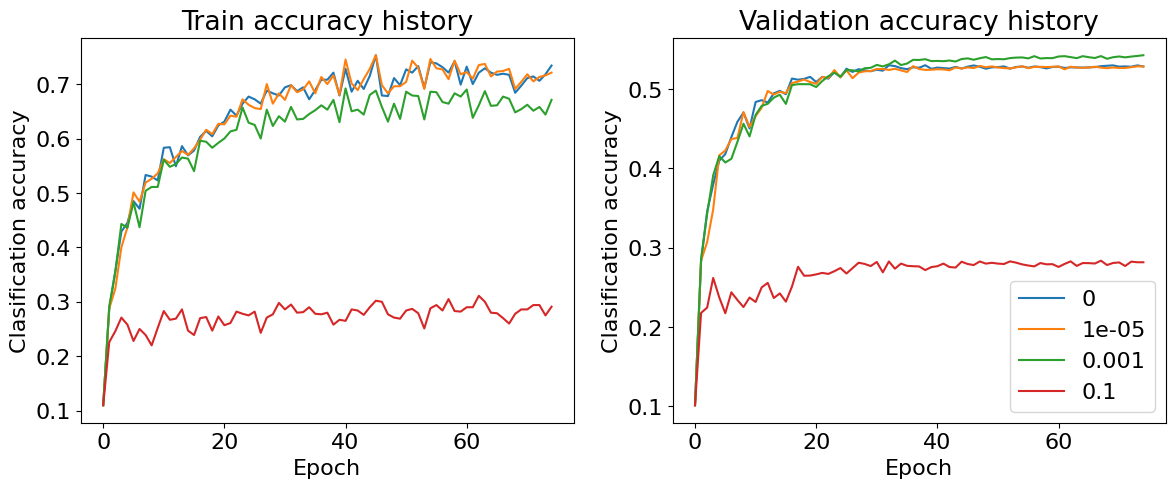
plot_acc_curves(stat_dict)
실제로 Regularization 계수가 너무 커지면 학습 데이터를 잘 학습하지 못하고, 검증 데이터의 정확도 역시 낮음을 확인할 수 있다. 이는 Regularization이 너무 커지면 모델이 데이터의 특징을 학습하기 보다는 모든 가중치가 0에 가깝게 줄어들도록 학습하기 때문이다. 이는 Underfitting으로 이어져 학습, 검증 정확도 모두 낮아지게된다.
- Learning Rate
import eecs598
from eecs598.a2_helpers import plot_acc_curves
from two_layer_net import TwoLayerNet
hs = 128
lrs = [1e-4, 1e-2, 1e0, 1e2]
reg = 1e-4
stat_dict = {}
for lr in lrs:
print('train with learning rate: {}'.format(lr))
# fix random seed before we generate a set of parameters
eecs598.reset_seed(0)
net = TwoLayerNet(3 * 32 * 32, hs, 10, device=data_dict['X_train'].device, dtype=data_dict['X_train'].dtype)
stats = net.train(data_dict['X_train'], data_dict['y_train'], data_dict['X_val'], data_dict['y_val'],
num_iters=3000, batch_size=1000,
learning_rate=lr, learning_rate_decay=0.95,
reg=reg, verbose=False)
stat_dict[lr] = stats
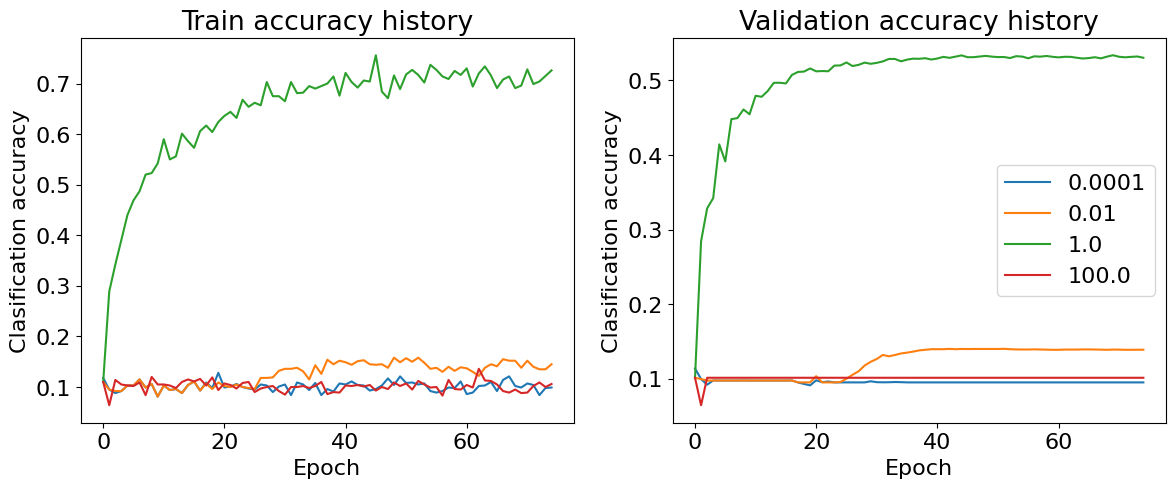
plot_acc_curves(stat_dict)
Learning Rate는 Weight Decacy의 비율을 결정한다. 즉, 계산한 Gradient를 기반으로 얼마나 Weight를 Update할지 결정하는 Parameter이다. Learning Rate가 너무 낮은 경우 학습 속도가 너무 느려 모델이 거의 학습하지 못함을 확인할 수 있으며, 너무 큰 경우 모델이 발산하여 Weight Update가 너무 급격하게 되어 학습하지 못함을 확인할 수 있다.
이처럼 Hyperparameter의 후보군을 결정하고 Tuning하여 최상의 Accuracy를 가지는 후보군과 이를 기반으로 학습한 모델의 성능을 평가 해 보자.
def nn_get_search_params():
"""
Return candidate hyperparameters for a TwoLayerNet model.
You should provide at least two param for each, and total grid search
combinations should be less than 256. If not, it will take
too much time to train on such hyperparameter combinations.
Returns:
- learning_rates: learning rate candidates, e.g. [1e-3, 1e-2, ...]
- hidden_sizes: hidden value sizes, e.g. [8, 16, ...]
- regularization_strengths: regularization strengths candidates
e.g. [1e0, 1e1, ...]
- learning_rate_decays: learning rate decay candidates
e.g. [1.0, 0.95, ...]
"""
learning_rates = []
hidden_sizes = []
regularization_strengths = []
learning_rate_decays = []
###########################################################################
# TODO: Add your own hyper parameter lists. This should be similar to the #
# hyperparameters that you used for the SVM, but you may need to select #
# different hyperparameters to achieve good performance with the softmax #
# classifier. #
###########################################################################
learning_rates = [0.5, 1, 1.5, 2]
hidden_sizes = [64, 128, 256, 512, 1024, 2048, 4096]
regularization_strengths = [1e-6, 1e-5, 1e-4, 1e-3]
learning_rate_decays = [93e-2, 95e-2, 97e-2]
###########################################################################
# END OF YOUR CODE #
###########################################################################
return (
learning_rates,
hidden_sizes,
regularization_strengths,
learning_rate_decays,
)
nn_get_search_params는 Hyperparameter의 후보군을 반환하는 함수이다. 해당 후보 외에 여러 Parameter 후보군을 생성하여 실험적으로 가장 Accuracy가 높은 후보를 추후 채택하였다.
def find_best_net(
data_dict: Dict[str, torch.Tensor], get_param_set_fn: Callable
):
"""
Tune hyperparameters using the validation set.
Store your best trained TwoLayerNet model in best_net, with the return value
of ".train()" operation in best_stat and the validation accuracy of the
trained best model in best_val_acc. Your hyperparameters should be received
from in nn_get_search_params
Inputs:
- data_dict (dict): a dictionary that includes
['X_train', 'y_train', 'X_val', 'y_val']
as the keys for training a classifier
- get_param_set_fn (function): A function that provides the hyperparameters
(e.g., nn_get_search_params)
that gives (learning_rates, hidden_sizes,
regularization_strengths, learning_rate_decays)
You should get hyperparameters from
get_param_set_fn.
Returns:
- best_net (instance): a trained TwoLayerNet instances with
(['X_train', 'y_train'], batch_size, learning_rate,
learning_rate_decay, reg)
for num_iter times.
- best_stat (dict): return value of "best_net.train()" operation
- best_val_acc (float): validation accuracy of the best_net
"""
best_net = None
best_stat = None
best_val_acc = 0.0
#############################################################################
# TODO: Tune hyperparameters using the validation set. Store your best #
# trained model in best_net. #
# #
# To help debug your network, it may help to use visualizations similar to #
# the ones we used above; these visualizations will have significant #
# qualitative differences from the ones we saw above for the poorly tuned #
# network. #
# #
# Tweaking hyperparameters by hand can be fun, but you might find it useful #
# to write code to sweep through possible combinations of hyperparameters #
# automatically like we did on the previous exercises. #
#############################################################################
# get hyperparameter candidate
learning_rates, hidden_sizes, regularization_strengths, learning_rate_decays = get_param_set_fn()
for lr in learning_rates:
for hs in hidden_sizes:
for rs in regularization_strengths:
for lrd in learning_rate_decays:
model = TwoLayerNet(3 * 32 * 32, hs, 10, device=data_dict['X_train'].device,\
dtype=data_dict['X_train'].dtype)
stats = model.train(data_dict['X_train'], data_dict['y_train'], data_dict['X_val'],\
data_dict['y_val'], num_iters=3000, batch_size=1000, learning_rate=lr, learning_rate_decay=lrd,\
reg=rs, verbose=False)
print("Train Parameter: ",lr, hs, rs, lrd, ", Acc: ", stats['val_acc_history'][-1])
if stats['val_acc_history'][-1] > best_val_acc:
best_net = model
best_stat = stats
best_val_acc = stats['val_acc_history'][-1]
print("Best Parameter: ", lr, hs, rs, lrd, "Best Accuracy: ", best_val_acc)
#############################################################################
# END OF YOUR CODE #
#############################################################################
return best_net, best_stat, best_val_acc
find_best_net는 후보 Hyperparameter의 조합으로 가능한 모든 경우에 수에 대하여 모델을 학습시키고 가장 높은 Accuracy를 가지는 모델과 결과, 정확도를 반환하는 함수이다.
여러 실험을 통해 최종적으로 가장 높은 Accuracy를 가지는 모델의 Hyperparameter는 다음과 같다.
- Learning Rate : 1.2
- hidden_sizes : 5012
- Regularization Strenghts : 5e-6
- Learning Rate Decays : 95e-2
학습 결과 Loss는 Iteratoin이 증가할수록 비선형적으로 적절히 감소하는 것을 확인할 수 있으며, Train, Validation Accuracy 역시 계속 증가함을 확인할 수 있다. 하지만, Train Accuracy에 비해 Validation Accruacy가 낮은 것으로 보아 Train Dataset에 Overfitting 되었음을 예측할 수 있다.

Validation Data에 대한 정확도는 55.8%로 다소 높지만, Overfitting 문제를 해결하면 더욱 높일 수 있을 것이라 예상한다.
# Check the validation-set accuracy of your best model
y_val_preds = best_net.predict(data_dict['X_val'])
val_acc = 100 * (y_val_preds == data_dict['y_val']).double().mean().item()
print('Best val-set accuracy: %.2f%%' % val_acc)
# Best val-set accuracy: 55.86%
현재 Capacity가 매우 커서 자세히는 보이지 않지만, 이전과는 달리 특정한 패턴(엣지 등)이 보이는 것을 확인할 수 있다.

실제로 Test Dataset에 대한 Accurcay 역시 55.73%로 준수한 편이다.
y_test_preds = best_net.predict(data_dict['X_test'])
test_acc = 100 * (y_test_preds == data_dict['y_test']).double().mean().item()
print('Test accuracy: %.2f%%' % test_acc)
# Test accuracy: 55.73%
'딥러닝 > Michigan EECS 498' 카테고리의 다른 글
| [EECS 498] Assignment 3. Fully Connected Networks...(2) (0) | 2025.01.07 |
|---|---|
| [EECS 498] Assignment 3. Fully Connected Networks...(1) (0) | 2025.01.06 |
| [EECS 498] Assignment 2. Two Layer Neural Network...(1) (0) | 2024.12.29 |
| [EECS 498] Assignment 2. Linear Classifier...(2) (2) | 2024.12.29 |
| [EECS 498] Assignment 2. Linear Classifier...(1) (1) | 2024.12.28 |


