
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- AlexNet
- r-cnn
- Python
- 딥러닝
- BFS
- ubuntu
- CNN
- 백준
- One-Stage Detector
- two-stage detector
- opencv
- real-time object detection
- 그래프 이론
- Mask Processing
- dynamic programming
- DP
- MySQL
- 머신러닝
- machine learning
- image processing
- dfs
- 강화학습
- deep learning
- NLP
- MinHeap
- C++
- LSTM
- eecs 498
- Reinforcement Learning
- YoLO
- Today
- Total
JINWOOJUNG
[EECS 498] Assignment 2. Linear Classifier...(2) 본문
본 포스팅은 Michigan Univ.의 EECS 498 강의를 수강하면서 공부한 내용을 정리하는 포스팅입니다.
[EECS 498] Assignment 2. Linear Classifier...(1)
본 포스팅은 Michigan Univ.의 EECS 498 강의를 수강하면서 공부한 내용을 정리하는 포스팅입니다.https://jinwoo-jung.tistory.com/123 [EECS 498] Assignment 1. k-NN...(2)본 포스팅은 Michigan Univ.의 EECS 498 강의를 수강
jinwoo-jung.com
Find Optimal Hyperparameter
초기 Accuracy는 9% 정도로 매우 낮음을 확인할 수 있다. Linear Classifier를 학습시키는 과정에서 조절할 수 있는 Hyperparameter는 Learning Rate, Regularization Strength가 있다. 결국에는 실험적으로 Accuracy가 좋아지는 Hyperparameter 값을 찾아야 한다.
- Get Hyperparameter Lists
def svm_get_search_params():
learning_rates = [1e-6, 1e-4, 1e-3, 5e-3]
regularization_strengths = [1e-3, 5e-3, 1e-2]
return learning_rates, regularization_strengths
실험하고자 하는 Learning Rate, Regularization Strengths Lists를 반환하는 함수이다.
- Test one Parameter set
def test_one_param_set(
cls: LinearClassifier,
data_dict: Dict[str, torch.Tensor],
lr: float,
reg: float,
num_iters: int = 2000,
):
train_acc = 0.0 # The accuracy is simply the fraction of data points
val_acc = 0.0 # that are correctly classified.
num_iters = 100
for i in range(num_iters):
cls.train(data_dict['X_train'], data_dict['y_train'], lr, reg)
train_acc = 100.0 * (data_dict['y_train'] == cls.predict(data_dict['X_train'])).double().mean().item()
val_acc = 100.0 * (data_dict['y_val'] == cls.predict(data_dict['X_val'])).double().mean().item()
return cls, train_acc, val_acc
입력받은 data_dict 안의 Training Dataset을 기반으로 Classifier를 학습시킨 뒤, Train, Validatation Dataset에 대한 Accuracy를 계산하여 반환하는 함수이다.
import os
import eecs598
from linear_classifier import LinearSVM, svm_get_search_params, test_one_param_set
# YOUR_TURN: find the best learning_rates and regularization_strengths combination
# in 'svm_get_search_params'
learning_rates, regularization_strengths = svm_get_search_params()
num_models = len(learning_rates) * len(regularization_strengths)
####
# It is okay to comment out the following conditions when you are working on svm_get_search_params.
# But, please do not forget to reset back to the original setting once you are done.
if num_models > 25:
raise Exception("Please do not test/submit more than 25 items at once")
elif num_models < 5:
raise Exception("Please present at least 5 parameter sets in your final ipynb")
####
i = 0
# results is dictionary mapping tuples of the form
# (learning_rate, regularization_strength) to tuples of the form
# (train_acc, val_acc).
results = {}
best_val = -1.0 # The highest validation accuracy that we have seen so far.
best_svm_model = None # The LinearSVM object that achieved the highest validation rate.
num_iters = 2000 # number of iterations
for lr in learning_rates:
for reg in regularization_strengths:
i += 1
print('Training SVM %d / %d with learning_rate=%e and reg=%e'
% (i, num_models, lr, reg))
eecs598.reset_seed(0)
# YOUR_TURN: implement a function that gives the trained model with
# train/validation accuracies in 'test_one_param_set'
# (note: this function will be used in Softmax Classifier section as well)
cand_svm_model, cand_train_acc, cand_val_acc = test_one_param_set(LinearSVM(), data_dict, lr, reg, num_iters)
if cand_val_acc > best_val:
best_val = cand_val_acc
best_svm_model = cand_svm_model # save the svm
results[(lr, reg)] = (cand_train_acc, cand_val_acc)
# Print out results.
for lr, reg in sorted(results):
train_acc, val_acc = results[(lr, reg)]
print('lr %e reg %e train accuracy: %f val accuracy: %f' % (
lr, reg, train_acc, val_acc))
print('best validation accuracy achieved during cross-validation: %f' % best_val)
# save the best model
path = os.path.join(GOOGLE_DRIVE_PATH, 'svm_best_model.pt')
best_svm_model.save(path)
svm_get_search_params()를 통해 가능한 경우의 Hyperparameter Lists를 구한 뒤, 각 경우에 대하여 Linear Classifier를 학습시키고, Validation Accuracy가 가장 큰 Parameter의 조합을 찾고 해당 모델을 저장하는 코드이다.
Training SVM 1 / 12 with learning_rate=1.000000e-06 and reg=1.000000e-03
Training SVM 2 / 12 with learning_rate=1.000000e-06 and reg=5.000000e-03
Training SVM 3 / 12 with learning_rate=1.000000e-06 and reg=1.000000e-02
Training SVM 4 / 12 with learning_rate=1.000000e-04 and reg=1.000000e-03
Training SVM 5 / 12 with learning_rate=1.000000e-04 and reg=5.000000e-03
Training SVM 6 / 12 with learning_rate=1.000000e-04 and reg=1.000000e-02
Training SVM 7 / 12 with learning_rate=1.000000e-03 and reg=1.000000e-03
Training SVM 8 / 12 with learning_rate=1.000000e-03 and reg=5.000000e-03
Training SVM 9 / 12 with learning_rate=1.000000e-03 and reg=1.000000e-02
Training SVM 10 / 12 with learning_rate=5.000000e-03 and reg=1.000000e-03
Training SVM 11 / 12 with learning_rate=5.000000e-03 and reg=5.000000e-03
Training SVM 12 / 12 with learning_rate=5.000000e-03 and reg=1.000000e-02
lr 1.000000e-06 reg 1.000000e-03 train accuracy: 24.882500 val accuracy: 25.030000
lr 1.000000e-06 reg 5.000000e-03 train accuracy: 24.882500 val accuracy: 25.030000
lr 1.000000e-06 reg 1.000000e-02 train accuracy: 24.882500 val accuracy: 25.030000
lr 1.000000e-04 reg 1.000000e-03 train accuracy: 37.940000 val accuracy: 36.730000
lr 1.000000e-04 reg 5.000000e-03 train accuracy: 37.932500 val accuracy: 36.720000
lr 1.000000e-04 reg 1.000000e-02 train accuracy: 37.917500 val accuracy: 36.700000
lr 1.000000e-03 reg 1.000000e-03 train accuracy: 41.440000 val accuracy: 38.990000
lr 1.000000e-03 reg 5.000000e-03 train accuracy: 41.335000 val accuracy: 38.960000
lr 1.000000e-03 reg 1.000000e-02 train accuracy: 41.247500 val accuracy: 38.960000
lr 5.000000e-03 reg 1.000000e-03 train accuracy: 43.017500 val accuracy: 39.370000
lr 5.000000e-03 reg 5.000000e-03 train accuracy: 42.742500 val accuracy: 39.400000
lr 5.000000e-03 reg 1.000000e-02 train accuracy: 42.507500 val accuracy: 39.240000
best validation accuracy achieved during cross-validation: 39.400000
Saved in drive/My Drive/SPA_Lab/A2/svm_best_model.pt
실제 학습시킨 결과 lr = 5e-3, reg = 5e-3인 경우 Validation Accuracy가 39.4%로 가장 높음을 확인할 수 있다.
실제로 각 Parameter에 따른 Accuracy를 비교한 결과 아래와 같다.
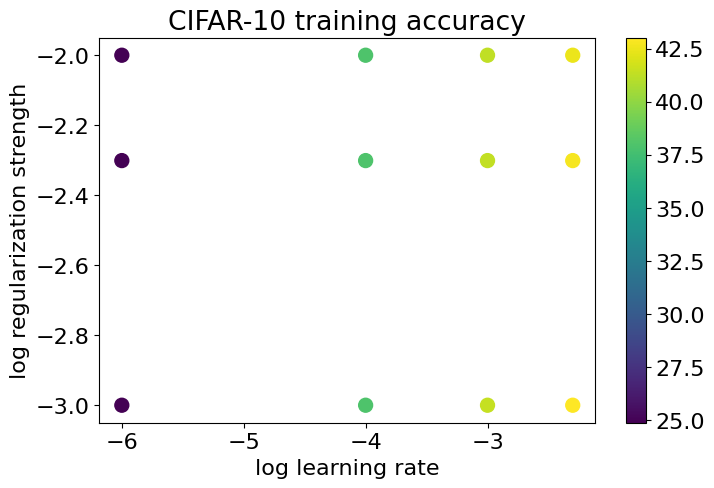
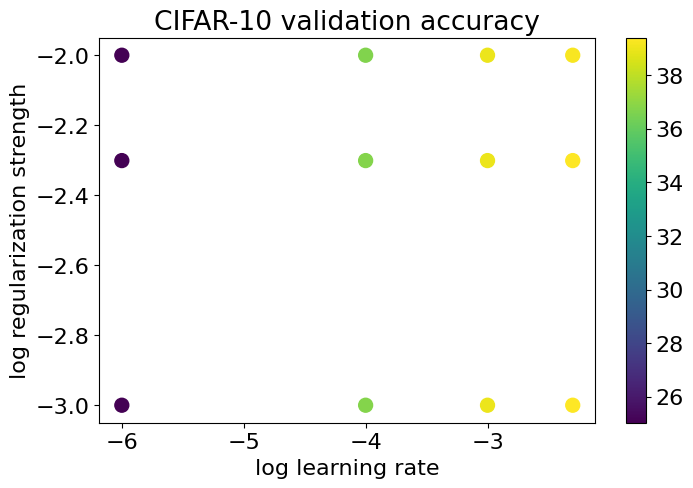
최종적인 Hyperparameter가 결정되었다면 실제 num_iters로 학습시킨 뒤 Test Dataset에 대한 Accuracy를 확인 해 보자.
import eecs598
eecs598.reset_seed(0)
y_test_pred = best_svm_model.predict(data_dict['X_test'])
test_accuracy = torch.mean((data_dict['y_test'] == y_test_pred).double())
print('linear SVM on raw pixels final test set accuracy: %f' % test_accuracy)
# linear SVM on raw pixels final test set accuracy: 0.361500
Test Accuracy는 생각보다 낮다,,추후 다른 조합에 대해서도 수행 할 예정이다.
w = best_svm_model.W[:-1,:] # strip out the bias
w = w.reshape(3, 32, 32, 10)
w = w.transpose(0, 2).transpose(1, 0)
w_min, w_max = torch.min(w), torch.max(w)
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
for i in range(10):
plt.subplot(2, 5, i + 1)
# Rescale the weights to be between 0 and 255
wimg = 255.0 * (w[:, :, :, i].squeeze() - w_min) / (w_max - w_min)
plt.imshow(wimg.type(torch.uint8).cpu())
plt.axis('off')
plt.title(classes[i])
해당 모델의 Bias Term을 제외시킨 뒤, 각 Class에 대한 입력 영상과 동일한 크기로 변형시킨 뒤 시각화를 하면 아래와 같다. 뭔가 형상을 띄는 것 같기는 한데, 정확하게 이해할 순 없다.

Softmax Classifier
이번엔 Softmax Classifier에 대하여 동일하게 학습, 검증, 테스트 과정을 구현 해 보자.
Softmax의 Probability를 다시한번 살펴보면 다음과 같다.
$$ p_i = \frac{e^{s_i}}{\sum_je^{s_j}}$$
그리고 Cross-Entropy Loss는 다음과 같다.
$$ L_i = -logP(Y=y_i | X = x_i) $$
최종적으로 우리가 구해야 하는 Gradient는 Chain Rule을 이용하면 다음과 같이 계산할 수 있다.
$$\frac{\partial L}{\partial W}=\frac{\partial L}{\partial p}\times \frac{\partial p}{\partial s}\times \frac{\partial s}{\partial W}$$
먼저 $\frac{\partial L}{\partial p_j^{(i)}} $에 대해 먼저 계산 해 보면 다음과 같다. Cross-Entropy Loss가 $j==y_i$일 때만 존재하기에 아래와 같이 계산할 수 있다. 이때, $ p_j^{(i)}$는 i번째 Input에 대한 Class j의 Probability를 의미한다.
$$ \frac{\partial L}{\partial p_j^{(i)}} = \left\{\begin{matrix}- \frac{1}{p_{y_i}} \quad , if \, j == y_i \\ 0 \quad \quad , if \; j != y_i \end{matrix}\right.$$
다음으로 $\frac{\partial p_j^{(i)}}{\partial s_k} $ 를 계산하면 다음과 같다. 분모항이 모든 Class에 대한 exp(score)의 합임을 기억하자.
$\frac{\partial p_j^{(i)}}{\partial s_k} $ 를 다시한번 정의하면 다음과 같이 정의할 수 있다.
$$\frac{\partial p_j^{(i)}}{\partial s_k} = \frac{\partial }{\partial s_k}\left ( \frac{e^{s_j}}{\sum_l e^{s_l}} \right )$$
해당 미분은 $j==k$와 $j!=k$인 2가지 경우로 나누어서 생각할 수 있다. 먼저 $j==k$인 경우는 다음과 같다.
$$\frac{\partial p_j^{(i)}}{\partial s_k} = \frac{e^{s_j}\left (\sum_l e^{s_l} \right ) - e^{s_j}e^{s_j}}{\left (\sum_l e^{s_l} \right )^2}=\frac{e^{s_j}}{\sum_l e^{s_l}}\left ( \frac{\sum_l e^{s_l}-e^{s_j}}{\sum_l e^{s_l}} \right )=p_j\left ( 1-p_j \right ), \quad if \; j==k$$
만약, $j!=k$인 경우는 다음과 같다.
$$\frac{\partial p_j^{(i)}}{\partial s_k} = \frac{\frac{\partial }{\partial s_k}e^{s_j}\left (\sum_l e^{s_l} \right ) - e^{s_j}e^{s_k}}{\left (\sum_l e^{s_l} \right )^2}=\frac{0 - e^{s_j}e^{s_k}}{\left ( \sum_l e^{s_l} \right )^2}=-p_jp_k, \quad if \; j!=k$$
마지막으로 $\frac{\partial s_j}{\partial W[:, j}$는 $s_j = X[i]W[:, j]$임을 이용하면 쉽게 유도할 수 있다.
$$\frac{\partial s_j}{\partial W[:, j} = X[i]$$
위 과정이 이해가 안되면 전부 하나하나 손으로 계산해 보길 추천한다.
- Naive Softmax Loss
def softmax_loss_naive(
W: torch.Tensor, X: torch.Tensor, y: torch.Tensor, reg: float
):
"""
Softmax loss function, naive implementation (with loops). When you implment
the regularization over W, please DO NOT multiply the regularization term by
1/2 (no coefficient).
Inputs have dimension D, there are C classes, and we operate on minibatches
of N examples.
Inputs:
- W: A PyTorch tensor of shape (D, C) containing weights.
- X: A PyTorch tensor of shape (N, D) containing a minibatch of data.
- y: A PyTorch tensor of shape (N,) containing training labels; y[i] = c means
that X[i] has label c, where 0 <= c < C.
- reg: (float) regularization strength
Returns a tuple of:
- loss as single float
- gradient with respect to weights W; an tensor of same shape as W
"""
# Initialize the loss and gradient to zero.
loss = 0.0
dW = torch.zeros_like(W)
#############################################################################
# TODO: Compute the softmax loss and its gradient using explicit loops. #
# Store the loss in loss and the gradient in dW. If you are not careful #
# here, it is easy to run into numeric instability (Check Numeric Stability #
# in http://cs231n.github.io/linear-classify/). Plus, don't forget the #
# regularization! #
#############################################################################
for i in range(X.shape[0]):
scores = W.T.mv(X[i])
scores -= scores.max() # Overflow 방지
scores = torch.exp(scores)
prob = scores / scores.sum()
loss -= torch.log(prob[y[i]])
for j in range(W.shape[1]):
if j == y[i]:
dW[:, j] += (prob[j] -1) * X[i]
else:
dW[:, j] += prob[j] * X[i]
loss = loss / X.shape[0] + reg * torch.sum(W*W)
dW = dW / X.shape[0] + 2 * reg * W
#############################################################################
# END OF YOUR CODE #
#############################################################################
return loss, dW
Naive 방법이므로 명시적으로 Loop를 돌면서 계산하였다. 각 Input Image에 대하여 Score를 계산한 뒤 Probability를 계산하였다. 이때, scores를 max값으로 전체 빼줌으로써 지수함수 계산 시 Overflow(지수 함수의 결과 값이 매우 커짐)을 방지하였다.
이후 공식에 근거하여 Cross-Entropy를 계산한 뒤 Gradient를 계산하였다. 모든 Class 만큼 For Loop를 돌면서 $ j == y[i]$ 즉, 정답 Class인 경우와 아닌 경우를 나눠서 Gradient를 계산해 주었다. 이후 각각을 N(Input Data 개수)로 나눠준 뒤, Regularization Term을 고려하여 더해주었다.
import eecs598
from linear_classifier import softmax_loss_naive
eecs598.reset_seed(0)
# Generate a random softmax weight tensor and use it to compute the loss.
W = 0.0001 * torch.randn(3073, 10, dtype=data_dict['X_val'].dtype, device=data_dict['X_val'].device)
X_batch = data_dict['X_val'][:128]
y_batch = data_dict['y_val'][:128]
# YOUR_TURN: Complete the implementation of softmax_loss_naive and implement
# a (naive) version of the gradient that uses nested loops.
loss, _ = softmax_loss_naive(W, X_batch, y_batch, reg=0.0)
# As a rough sanity check, our loss should be something close to log(10.0).
print('loss: %f' % loss)
print('sanity check: %f' % (math.log(10.0)))
# loss: 2.302826
# sanity check: 2.302585
Softmax Loss는 초기 Weight에 대하여 $-log(\frac{1}{C})$을 보인다. 이는 Weight Matrix가 Random Value이기에, 각 클래스일 확률의 기댓값이 $\frac{1}{C}$이기 때문이다.
실제로 계산한 결과 $C$는 10이기 때문에, log(10)=2.3과 유사한 값을 가짐을 확인할 수 있다.
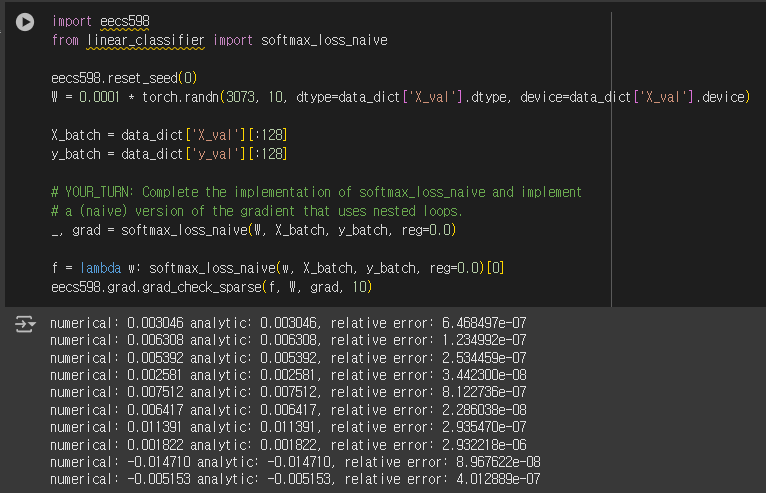
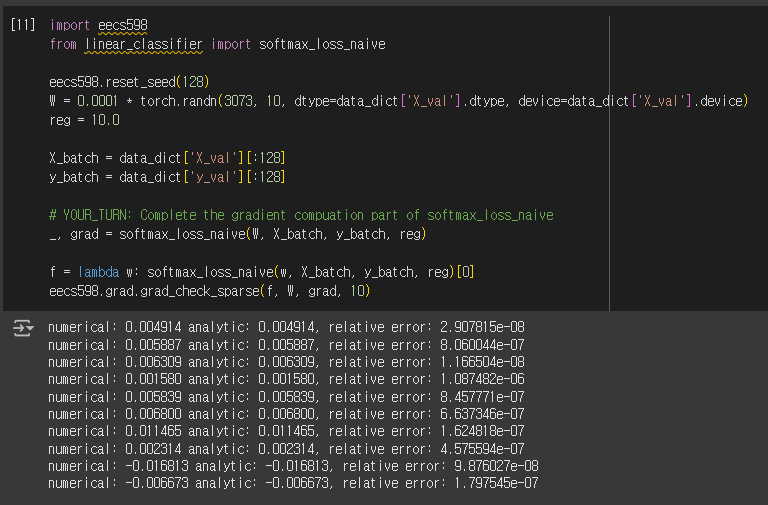
앞선 SVM Classifer과 동일하게 Gradient를 grad_check_sparse Method를 통해 검증 해 보면 1e-5보다 작은 매우 작은 오차를 가지기에 정확히 구현하였음을 확인할 수 있다. 이는 Regularization Term을 고려했을 때 역시 동일하다.
- Vectorize Softmax Loss
def softmax_loss_vectorized(
W: torch.Tensor, X: torch.Tensor, y: torch.Tensor, reg: float
):
"""
Softmax loss function, vectorized version. When you implment the
regularization over W, please DO NOT multiply the regularization term by 1/2
(no coefficient).
Inputs and outputs are the same as softmax_loss_naive.
"""
# Initialize the loss and gradient to zero.
loss = 0.0
dW = torch.zeros_like(W)
#############################################################################
# TODO: Compute the softmax loss and its gradient using no explicit loops. #
# Store the loss in loss and the gradient in dW. If you are not careful #
# here, it is easy to run into numeric instability (Check Numeric Stability #
# in http://cs231n.github.io/linear-classify/). Don't forget the #
# regularization! #
#############################################################################
scores = X.mm(W)
max_score = scores.max(axis = 1).values.view(-1, 1) # 각 행(Input Data)에 대한 Max Score
scores -= max_score
scores = torch.exp(scores)
prob = scores / scores.sum(axis = 1).view(-1, 1) # 각 행(Input Data)의 총 합으로 나눔 -> Prob
idx0 = torch.arange(0, X.shape[0])
loss -= torch.log(prob[idx0, y]).sum() # 각 Input Data의 정답 Class에 대한 Probability만 가져와 Loss 계산
loss = loss / X.shape[0] + reg * torch.sum(W*W)
prob[idx0, y] -= 1
dW = X.T.matmul(prob)
dW = dW / X.shape[0] + 2 * reg * W
#############################################################################
# END OF YOUR CODE #
#############################################################################
return loss, dW
Vectorize Softmax Loss의 경우는 명시적인 Loop 없이 구현 해 주었다. X.mm(W)로 전체 score를 계산한 뒤, 각 행에 대한 Max Score를 구하고 torch.view(-1,1)를 통해 행이 아닌 열로 변형하여 Broadcasting을 활용해 계산하였다.
이후 앞서 Naive 방법처럼 prob를 계산한 뒤, Loss의 경우 정답 클래스에 대해서만 계산하기 때문에 Integer Indexing을 사용하였다. 각 행에 대한 정답 클래스의 Probability만 가져와 log 함수를 씌워 Loss를 계산한 뒤 torch.sum()을 이용해 총 합을 구하여 사전 정의한 loss에 빼주었다.
Gradient의 경우 정답 클래스에 대해서만 (prob -1)*X이고, 나머지는 prob*X이므로, Integer Indexing을 통해 정답 클래스에 대한 확률은 전부 1씩 빼준 뒤, torch.matmul을 통해 Matrix Vector Multiply로 dW(Gradient)를 계산하였다. 이후 Loss, Gradient 모두 Regularization Term을 고려하여 더해주었다.
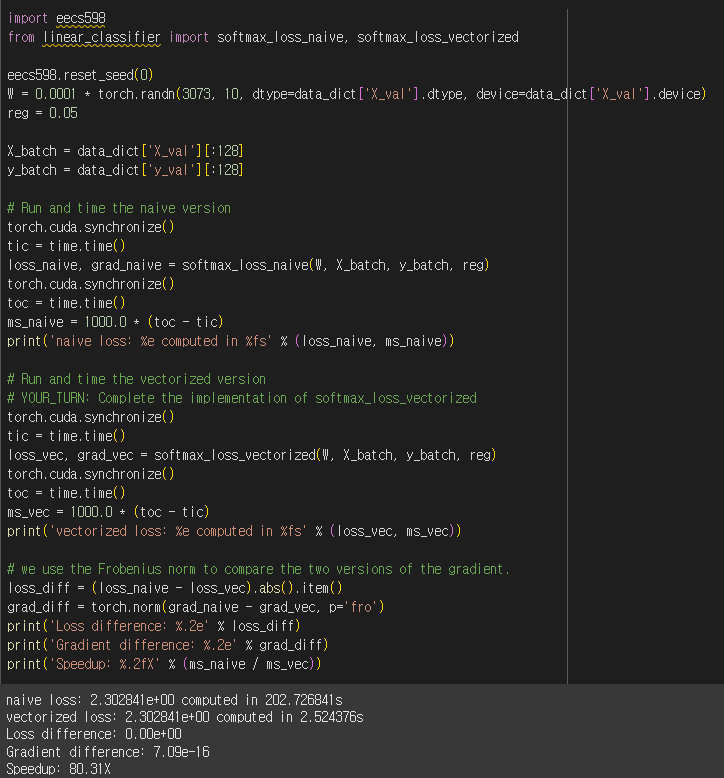
수행 결과 Naive Version과 오차는 거의 없지만, 연산 측면에서 80배의 성능을 보임을 확인할 수 있다.
- Train Softmax Classifier
import os
import eecs598
from linear_classifier import Softmax, softmax_get_search_params, test_one_param_set
# YOUR_TURN: find the best learning_rates and regularization_strengths combination
# in 'softmax_get_search_params'
learning_rates, regularization_strengths = softmax_get_search_params()
num_models = len(learning_rates) * len(regularization_strengths)
####
# It is okay to comment out the following conditions when you are working on svm_get_search_params.
# But, please do not forget to reset back to the original setting once you are done.
if num_models > 25:
raise Exception("Please do not test/submit more than 25 items at once")
elif num_models < 5:
raise Exception("Please present at least 5 parameter sets in your final ipynb")
####
i = 0
# As before, store your cross-validation results in this dictionary.
# The keys should be tuples of (learning_rate, regularization_strength) and
# the values should be tuples (train_acc, val_acc)
results = {}
best_val = -1.0 # The highest validation accuracy that we have seen so far.
best_softmax_model = None # The Softmax object that achieved the highest validation rate.
num_iters = 2000 # number of iterations
for lr in learning_rates:
for reg in regularization_strengths:
i += 1
print('Training Softmax %d / %d with learning_rate=%e and reg=%e'
% (i, num_models, lr, reg))
eecs598.reset_seed(0)
cand_softmax_model, cand_train_acc, cand_val_acc = test_one_param_set(Softmax(), data_dict, lr, reg, num_iters)
if cand_val_acc > best_val:
best_val = cand_val_acc
best_softmax_model = cand_softmax_model # save the classifier
results[(lr, reg)] = (cand_train_acc, cand_val_acc)
# Print out results.
for lr, reg in sorted(results):
train_acc, val_acc = results[(lr, reg)]
print('lr %e reg %e train accuracy: %f val accuracy: %f' % (
lr, reg, train_acc, val_acc))
print('best validation accuracy achieved during cross-validation: %f' % best_val)
# save the best model
path = os.path.join(GOOGLE_DRIVE_PATH, 'softmax_best_model.pt')
best_softmax_model.save(path)
SVM Classifier과 동일하게 Hyperparameter의 후보군을 생성한 뒤, 각각의 조합에 대하여 학습시키고 Validation Accuracy가 가장 높은 조합을 찾는다.
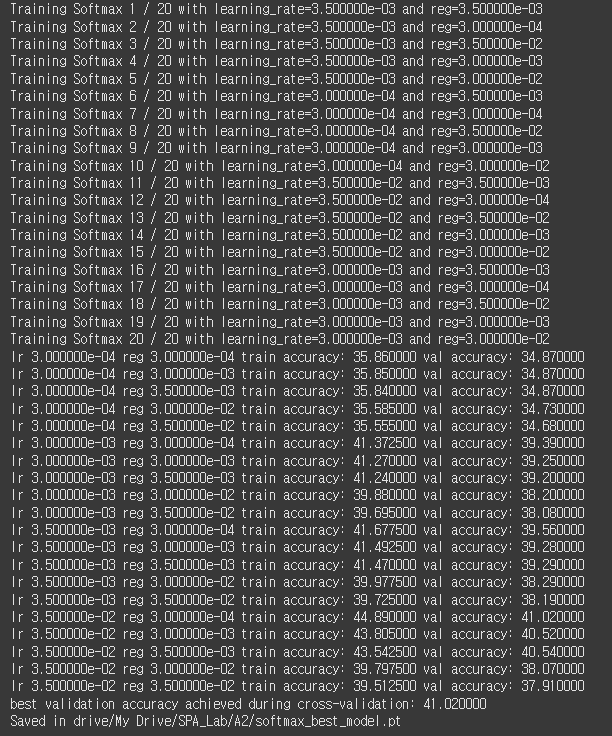
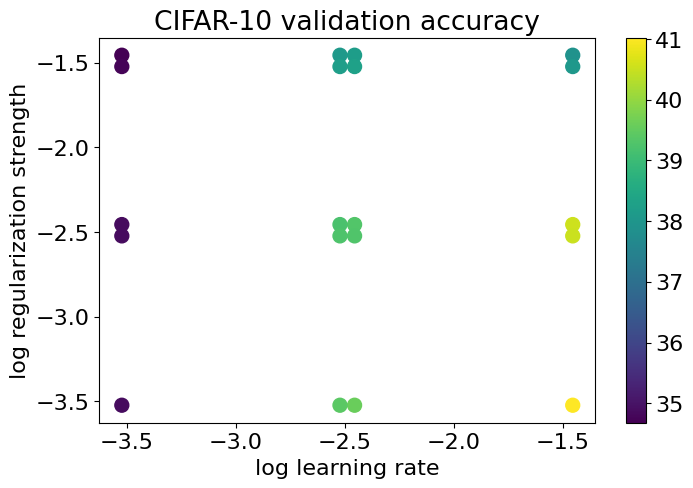
총 20가지의 조합 중 lr = 35e-2, reg = 3e-4 임을 확인할 수 있다. 각 조합에 대한 Accuracy는 다음과 같다.

y_test_pred = best_softmax_model.predict(data_dict['X_test'])
test_accuracy = torch.mean((data_dict['y_test'] == y_test_pred).double())
print('softmax on raw pixels final test set accuracy: %f' % (test_accuracy, ))
# softmax on raw pixels final test set accuracy: 0.411900
test dataset에 대한 정확도는 41.19%로 생각보다 정확하게 나왔다.
w = best_softmax_model.W[:-1,:] # strip out the bias
w = w.reshape(3, 32, 32, 10)
w = w.transpose(0, 2).transpose(1, 0)
w_min, w_max = torch.min(w), torch.max(w)
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
for i in range(10):
plt.subplot(2, 5, i + 1)
# Rescale the weights to be between 0 and 255
wimg = 255.0 * (w[:, :, :, i].squeeze() - w_min) / (w_max - w_min)
plt.imshow(wimg.type(torch.uint8).cpu())
plt.axis('off')
plt.title(classes[i])
실제로 모델의 Weight Matrix를 plot 해 보면 다음과 같다. Softmax Classifier 보다 더 정확도가 높고, 학습이 잘 되었기에 실제로 각 클래스의 객체처럼 보이지는 않지만, 무언가를 학습하고 있는 것 처럼 보이긴 한다. 하지만 뭔진 모른다.

'딥러닝 > Michigan EECS 498' 카테고리의 다른 글
| [EECS 498] Assignment 2. Two Layer Neural Network...(2) (0) | 2024.12.30 |
|---|---|
| [EECS 498] Assignment 2. Two Layer Neural Network...(1) (0) | 2024.12.29 |
| [EECS 498] Assignment 2. Linear Classifier...(1) (1) | 2024.12.28 |
| [EECS 498] Assignment 1. k-NN...(2) (0) | 2024.12.24 |
| [EECS 498] Assignment 1. k-NN...(1) (1) | 2024.12.24 |



