
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- LSTM
- MySQL
- 백준
- machine learning
- DP
- two-stage detector
- deep learning
- dynamic programming
- r-cnn
- Reinforcement Learning
- dfs
- eecs 498
- 머신러닝
- MinHeap
- YoLO
- 강화학습
- Mask Processing
- C++
- CNN
- ubuntu
- 딥러닝
- image processing
- opencv
- AlexNet
- BFS
- NLP
- One-Stage Detector
- real-time object detection
- Python
- 그래프 이론
- Today
- Total
JINWOOJUNG
[ YOLOv8 ] 학습된 모델 성능 분석(Confusion Matrix, Precision, Recall, Confidence, NMS) 본문
[ YOLOv8 ] 학습된 모델 성능 분석(Confusion Matrix, Precision, Recall, Confidence, NMS)
Jinu_01 2024. 8. 18. 11:41직접 구축한 Custom Datset을 기반으로 Yolov8 모델을 학습시켰다. 이제는 학습된 모델의 성능을 평가하기 위한 몇가지 방법을 알아보고, Yolo 모델을 학습 시 Validation Dataset을 기반으로 자동으로 계산되는 성능 평가 지표를 직접 분석 해 보자.
[ YOLOv8 ] Custom Dataset 학습(Google Colab)
https://jinwoo-jung.tistory.com/68 [ YOLOv8 ] Custom Dataset 구축(Roboflow)YOLOv8을 통한 Object Detection을 위해선 적합한 Model을 생성해야 한다.Model 학습을 위해선 Custom Dataset을 구축해야 하며, YOLOv8의 경우 Roboflow
jinwoo-jung.com
Custom Dataset
- Camera : Logitech Webcam
- Resolution : 640x480
- Location : K-City Proving Ground
- Vehicle : ERP-42
ERP-42 차량 전방에 부착한 Camera로 취득한 신호등 영상으로 Custom Dataset을 구축하였다. 차량이 실제 주행하는 환경에서 취득한 영상이기에 추가적인 Data Augmentation은 적용하지 않았다. Class는 총 6개로 Green, LeftGreen, Red, RedLeft, RedYellow, Yellow이다. 데이터 구성은 실제 차량이 신호등을 인식하여 정지하는 시나리오를 구성하여 취득하였고, 각 클래스당 데이터 수를 균등하게 하기위해 700개로 구성하였다. 이때, 학습 세트는 7:2:1의 비율로 Train, Test, Valid Data를 나누었다.
Model Train Result
앞서 포스팅한 방법데로 Yolov8 모델을 학습시킨다면, 자동으로 Confusion Matrix, F1/Precision/Recall-Confidence Curve 등을 구해준다.

학습된 최적의 모델은 weights/best.pt로 저장되고, 해당 모델의 성능이 다양한 방법으로 표현된다.
Confusion Matrix

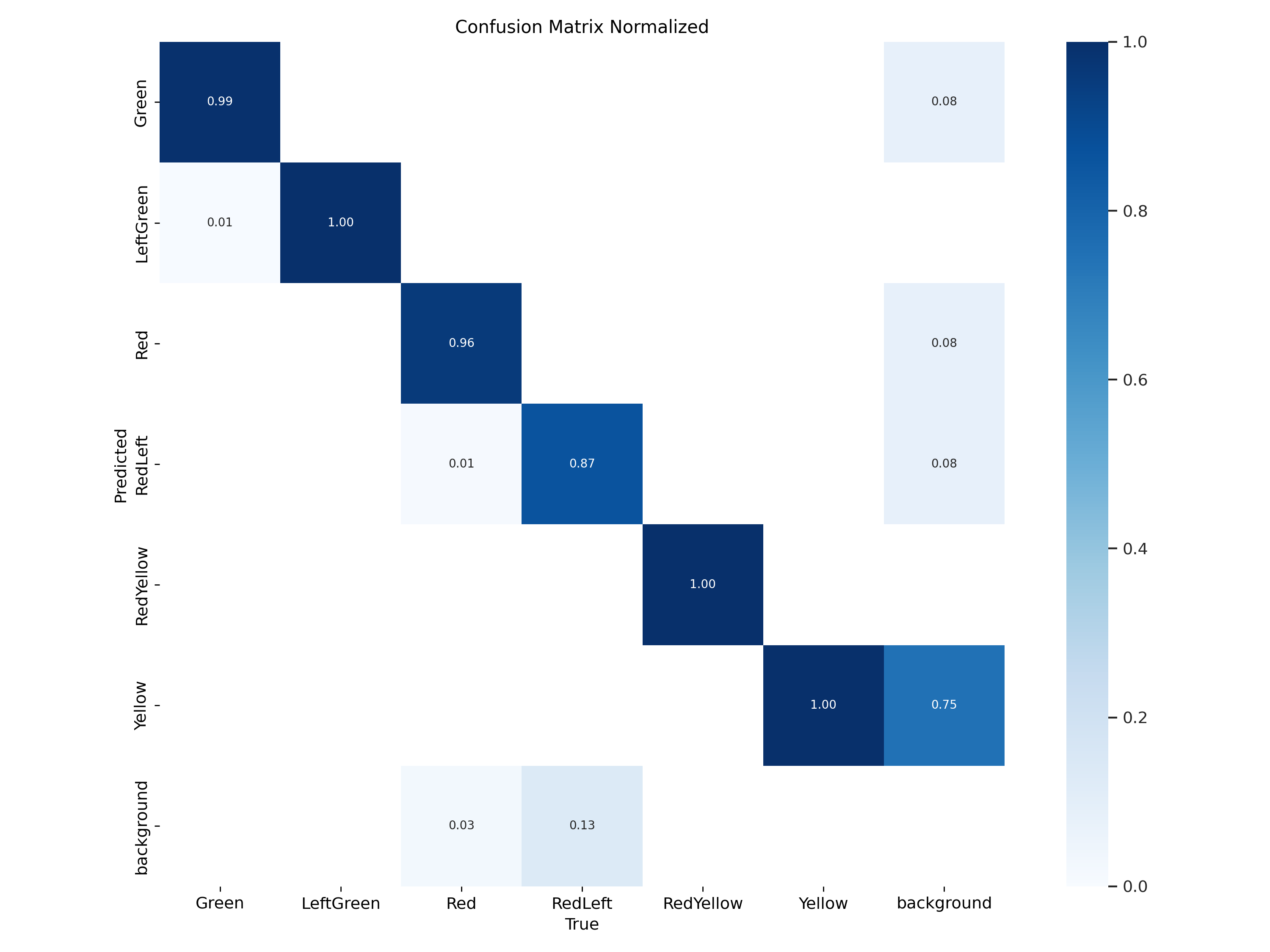
Confusion Matrix는 학습된 모델의 입력값과 예측값을 나타내는 테이블로, F1 Score, Accuracy, Precision, Recall를 계산하는 근거가 된다. Confusion Matrix의 가로축은 True Value, 세로축은 Predicted Value를 나타낸다. 대부분의 Class에서 좋은 성능을 보이고 있지만, 실제 RedLeft를 감지못하여 BackGround로 판단한 경우가 25건이 존재한다.


왼쪽이 True Value, 오른쪽이 Predicted Value이다. 확실히 RedLeft에 대하여 약간은 성능이 떨어짐을 확인할 수 있다.
Precision, Recall 등을 사용하여 분석하기 이전, TP, TN, FP, FN을 Object Detection 관점에서 이해가 필요하다.
- True Positive(TP) : 실제 True & 예측 True = 검출되야 할 객체가 검출됨
- True Negative(TN) : 실제 False & 예측 False = 검출되지 말아야 할 것이 검출되지 않음
- False Positive(FP) : 실제 False & 예측 True = 검출되지 말아야 할 것이 검출됨
- False Negative(FN) : 실제 True & 예측 False = 검출되야 할 객체가 검출되지 않음
Object Detection에서는 객체에 대한 Classification(Class)와 Localization(Position)이 모두 이루어 지기 때문에, True Value와 Predicted Value가 같다고 확인하기 위해서는 검출한 객체의 Class와 Position을 모두 확인해야 한다. 이때, Position을 확인하기 위해서 True Value와 Predicted Value의 Bounding Box를 이용하여 IoU를 계산하게 된다.
Intersection over Union(IoU)


IoU는 True, Predicted Value의 Bounding Box를 이용하는데, 두 Bounding Box의 교집합/ 두 Bounding Box의 합집합이라고 생각하면 쉽다. 동일한 객체이므로 두 Bounding Box의 크기가 유사하다고 가능하면, 두 Bounding Box가 겹쳐야 높은 IoU가 계산되기에, Localization이 잘 됬다고 판단하는 기준은 0.5 정도의 Valu가 되는 것 같다.
따라서 IoU와 Class 개념을 적용하여 TP, FP, FN을 다시 정의 해 보면 다음과 같다.
- TP : 검출해야 할 객체의 Class가 True와 동일하고, IoU가 0.5(Threshold) 보다 높음
- FP : 검출은 했지만, Class가 True와 다르거나, IoU가 0.5보다 작음
- FN : 검출해야 할 객체를 검출하지 못함.
Precision(정밀도)
Precision은 검출(P)한 경우 중 True, Predicted Value가 모두 Positive로 일치하는 비율을 의미한다.
$$Precision = \frac{TP}{TP + FP} $$
즉, Object Detection Model이 검출한 결과가 실제 Object와 일치하는지 나타내는 성능 지표로, 얼마나 잘 탐지하는지를 나타낸다.
Recall(재현율)
Recall은 실제 Positive인 경우 중 True, Predicted Value가 모두 Positive로 일치하는 비율을 의미한다.
$$Precision = \frac{TP}{TP + FN} $$
즉, Object Detection Model이 검출한 결과가 실제 Object를 정확히 검출하는지 나타내는 성능 지표이다.
Precision - Recall Trade Off
두 성능지표 낮으면 안되는 지표이지만, 동시에 높을 순 없다.
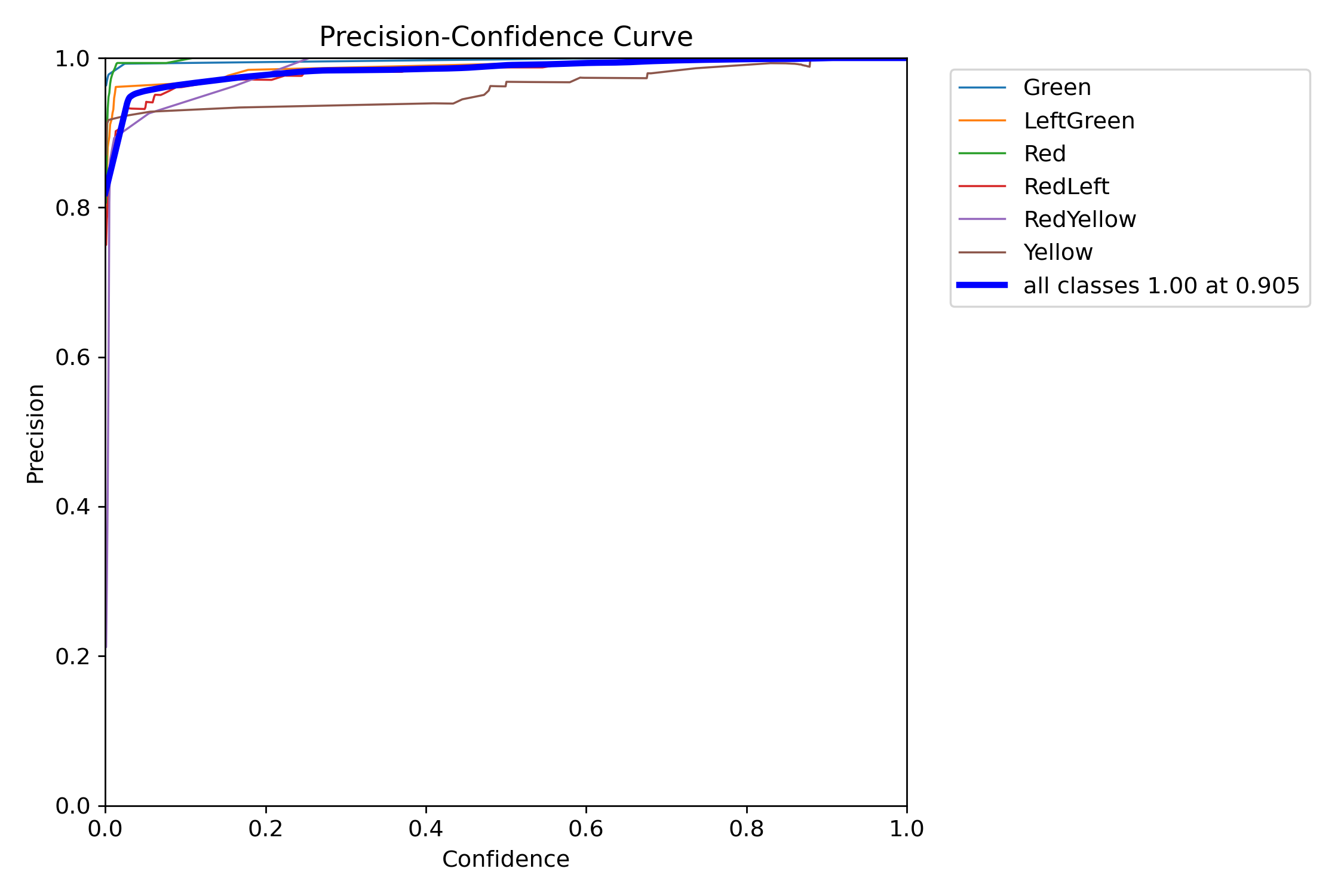

실제로, Precision-Confidence Curve, Recall-Confidence Curve를 보면 Precision의 경우 점점 높아지고, Recall의 경우 점점 낮아짐을 확인할 수 있다. 따라서 Precsion 또는 Recall을 높이기 위해서는 Confidence Threshold를 적절히 조절해야 한다.
Confidence Threshold는 NMS에 영향을 주기 때문에, 그에 따라 Precision, Recall의 결과도 달라진다.
Non-Maximum Suppression(NMS)
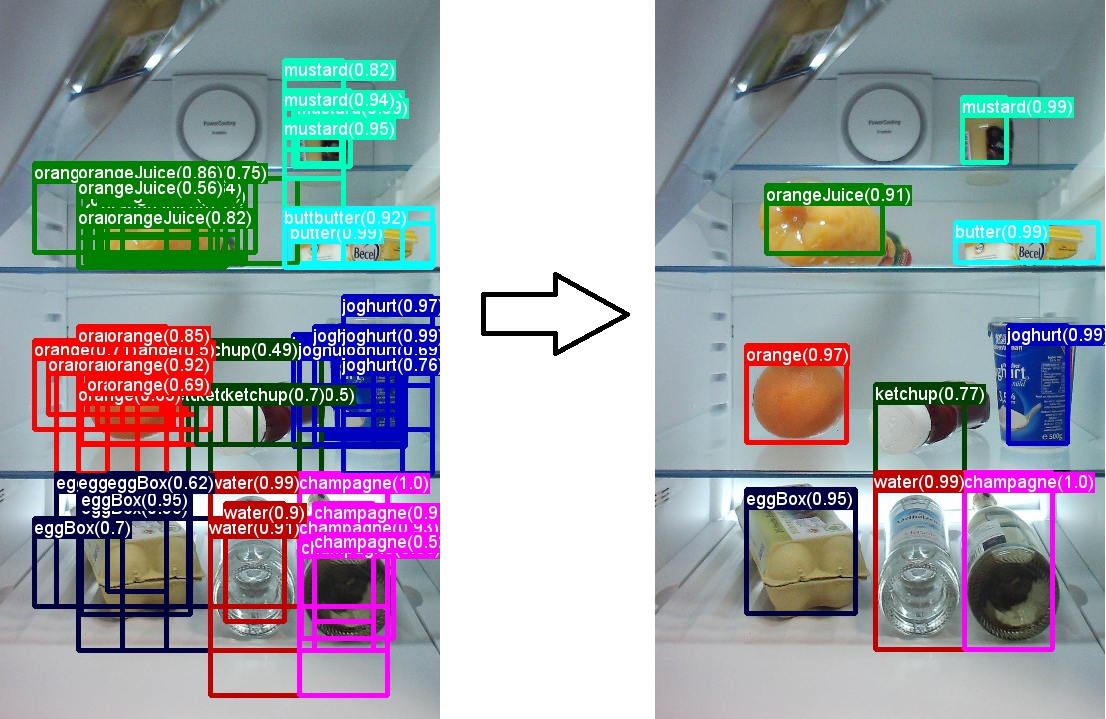
NMS는 동일한 물체를 가르키는 다수의 Bounding Box(검출 결과)의 중복을 제거하기 위함이다. 즉, 객체에 대하여 검출된 Bounding Box 중 유사한 위치에 있는 Bounding Box를 제거하고(동일 객체에 대한), 최적의 Bounding Box를 선택하는 알고리즘이다.
알고리즘을 간략하게 설명 할 것인데, 하나 주의해야 할 점은 특정 클래스나 Bounding Box가 아닌, 하나의 Frame에 대하여 검출한 결과에 대하여 수행하는 알고리즘임을 기억하자.
- Confidence Threshold 이하의 Bounding Box는 제거한다.
- 제거된 Bounding Box에 대하여 Confidence를 기준으로 내림차순 정렬한다.
- Confidence가 높은 Bounding Box에 대하여, 해당 Bounding Box와 IoU가 특정 Threshold 이상인 Bounding Box를 제거
- 이 과정에서 동일한 객체에 대하여 유일한 최적의 Bounding Box를 특정할 수 있다.
NMS 알고리즘을 이해했다면, Confidence Threshold가 높을수록, IoU Threshold가 낮을수록 더 많은 Bounding Box가 제거됨을 알 수 있을 것이다.
다시 Precision-Recall Trade Off로 돌아온다면, Confidence Threshold가 낮아진다면, 객체일 가능성이 낮은 Bounding Box까지 남아있기에 Predicted 된 많은 Bounding Box가 존재한다. 즉, FP는 증가하고, FN는 감소할 것이기 때문에 Precision은 낮아지고, Recall은 증가하게 된다.
Confidence Threshold가 높아진다면, 객체일 가능성이 높은 Bounding Box만 남아있기에, Predicted 된 Bounding Box가 적어질 것이다. 따라서 FP는 낮아지고, FN은 높아질 것이기 때문에 Precision은 낮아지고, Recall은 증가한다.
따라서 Confidence Threshold를 잘 조절 해 줘야 한다.
mAP(mean Average Precision)
따라서 Object Detection의 성능 지표는 Precision, Recall을 통해 평가되는데, 이를 위해 Precision-Recall Curve를 사용한다.

Precision-Recall Curve는 Confidece Threshold에 따라 얻어진 Recall의 변화에 따른 Precision이다. 여기서 AP(Average Precision)는 Precision-Recall Curve의 아래 면적을 의미한다. 이는 하나의 Class에 대함이고, 모든 객체들에 대한 AP의 평균이 바로 mAP이다.

위 그래프는 Yolov Version에 따른 mAP인데, 확실이 YOLOv8로 넘어오면서 성능이 향상되었음을 확인할 수 있다.
'딥러닝' 카테고리의 다른 글
| [YOLO 11] Real Time Object Detection (0) | 2024.12.23 |
|---|---|
| [ YOLOv8 ] Custom Dataset 학습(Google Colab) (4) | 2024.05.07 |
| [ YOLOv8 ] Custom Dataset 구축(Roboflow) (0) | 2024.05.07 |


