
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- real-time object detection
- dfs
- eecs 498
- MySQL
- 딥러닝
- Mask Processing
- AlexNet
- ubuntu
- deep learning
- dynamic programming
- CNN
- opencv
- 백준
- MinHeap
- One-Stage Detector
- 그래프 이론
- YoLO
- Python
- NLP
- BFS
- Reinforcement Learning
- r-cnn
- LSTM
- 강화학습
- machine learning
- two-stage detector
- image processing
- 머신러닝
- C++
- DP
- Today
- Total
JINWOOJUNG
[ DB ] 데이터베이스...1 본문
본 포스팅은 인하대학교 최원익교수님의 "데이터베이스설계" 수업에서 진행한 프론트, 백엔드 실습 관련 정리하는 포스팅입니다. 백엔드, 프론트엔드는 전문 분야가 아니기에 공부용으로 올리는 포스팅이며 오류사항이 있을 수 있습니다.
- 데이터 베이스 생성하기

mysql -uroot -p
먼저 root 이름으로 MySQL을 실행시킨다.

dbdesign이라는 이름으로 데이터베이스를 생성한다. 이후 새로운 데이터베이스 사용자를 생성한다. MySQL에서는 사용자의 이름이 username@host 형식으로 지정된다. 위의 경우 사용자의 이름은 dbuser이며, %의 의미는 모든 IP 주소에서 접근 가능함을 의미한다. 만약 특정 IP주소에서만 접근 가능하도록 하고싶으면, 'username'@'192.168.0.100' 이런식으로 지정하면 된다. 이후 identified by 'passward'는 비밀번호를 지정하는 구문이다.
이후 grant를 통해 권한을 부여하며, flush privileges를 통해 DB에 권한 부여를 적용한다.
- 서버 시간 설정
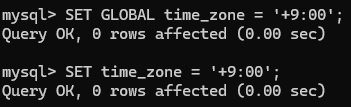
이후 생성한 데이터베이스의 서버 시간을 설정 해 준다.
- User 접근

mysql -udbuser -p dbdesign
새롭게 생성한 dbuser라는 이름으로 dbdesign 데이터베이스에 접근한다.
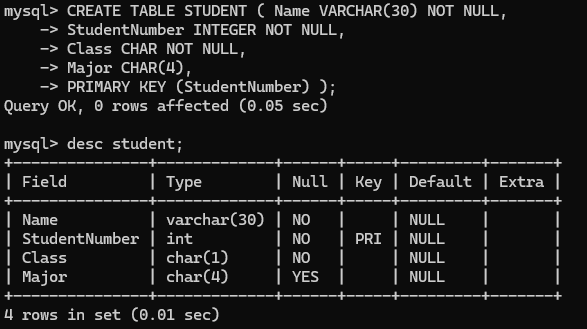
아무것도 생성하지 않았으므로 STUDENT Table를 생성하자. student Table에 해당되는 각 Field, Data Type, NULL이 가능한지 여부, Primary Key에 해당하는 Field를 입력 해 준다. 이때, VARCHAR, CHAR 두 DataType이 있는데 약간의 차이가 있다.
VARCHAR : 가변길이. 실제 데이터의 길이에 따라 공간을 다르게 차지함.
CHAR : 고정길이. 지정된 길이만큼의 공간을 차지함.
Ex) 둘다 길이를 10으로 지정하고, 데이터가 5만큼 들어갔다면, VARCHAR DataType의 경우 5의 공간을 차지하지만, CHAR DataType의 경우 10을 그대로 차지한다.
생성한 테이블의 Schema(스키마)를 확인하기 위해서는 desc 명령어를 통해 확인 가능하다.
Schema는 데이터베이스(Table)의 구조를 정의하는 개념이다.
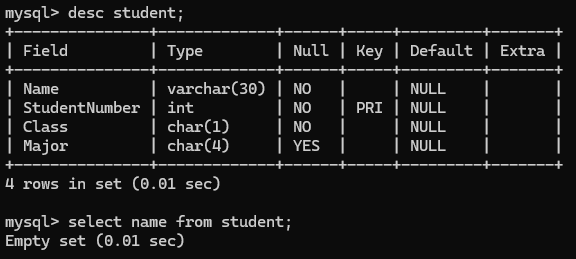
다음과 같이 Table 생성 시 정의한 구조를 확인할 수 있다. 현재는 Table을 생성한 뒤 데이터를 추가하지 않았기에 아무것도 없음을 확인할 수 있다.

데이터를 추가할 때에는 insert를 통해 추가할 수 있으며, student Table의 모든 데이터를 출력한 결과 정상적으로 데이터를 입력할 수 있음을 확인할 수 있다.
하지만, Database의 Table이 많아지고 수많은 데이터를 넣는 작업을 일일이 명령 프롬프트에서 수행하면 매우 힘들다. 따라서 MySQL Workbench를 활용할 것이다.

Workbench에 들어가보면, 앞서 생성한 dbdesign Database, student Table이 그대로 남아있음을 확인할 수 있다.

다음과 같이 명령 프롬프트에서 진행한 것과 동일한 결과를 확인할 수 있다. 이제 새로운 테이블을 생성하고 데이터를 추가 해 보자.
- employee Table
CREATE TABLE employee (
emp_id INT PRIMARY KEY,
first_name VARCHAR(40),
last_name VARCHAR(40),
birth_day DATE,
sex VARCHAR(1),
salary INT,
super_id INT,
branch_id INT
);
Table 생성 시 PRIMARY KEY를 바로 설정할 수 있다. 이때, NULL에 대한 설정을 하지 않으면, 자동으로 NULL을 허용하며, PRIMARY KEY의 경우 NOT NULL로 설정된다.
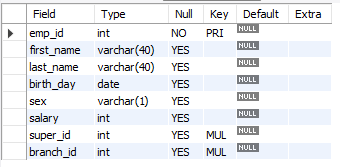
desc를 통해 스키마를 확인해 보면 잘 설정됨을 확인할 수 있다.
- branch Table
CREATE TABLE branch (
branch_id INT PRIMARY KEY,
branch_name VARCHAR(40),
mgr_id INT,
mgr_start_date DATE,
FOREIGN KEY(mgr_id) REFERENCES employee(emp_id) ON DELETE SET NULL
);
마지막에 보면 FOREIGN KEY(외래키)를 설정하는데, 잠깐 살펴보고 넘어가자.
PRIMARY KEY(기본 키)
기본 키는 테이블에서 각 행을 고유하게 식별하는데 사용되는 키이다.
기본적으로 각 테이블에는 하나의 PRIMARY KEY가 존재하며, 기본 키는 고유하고 NULL 값이 허용되지 않는다.
FOREIGN KEY(외래 키)
외래키는 다른 테이블의 PRIMARY KEY를 참조하는 Feild이다.
외래키는 두 테이블 간의 참조 무결성을 유지하는데 사용된다. 즉, 외래키를 통해 관계가 형성되는 두 테이블의 데이터가 일관성을 보장할 수 있도록 한다.
branch Table의 mgr_id Feild는 외래키로 employee Table의 emp_id Feild를 참조한다. 따라서 branch Tabled의 bgr_id Feild Data는 employee Table의 emp_id Data 중 일부여야 한다. 이때, ON DELETE SET NULL은 외래키가 참조하는 값 즉, employee Table의 해당 emp_id가 삭제되면, branch Table의 mgr_id는 자동으로 NULL로 설정됨을 의미한다.
- ALTER SQL
Table을 생성한 뒤 Table의 구조를 변경하기 위해서는 ALTER SQL을 사용해야 한다.
ALTER TABLE employee ADD FOREIGN KEY(super_id) REFERENCES employee(emp_id) ON DELETE SET NULL;
위 명령의 경우, 이미 생성한 employee Table의 super_id Filed를 외래키로 설정하며, employee Table의 emp_id를 참조한다는 의미이다.
- INSERT SQL
생성된 Table에 새로운 데이터를 추가할 때는 INSERT SQL을 사용해야 한다.
INSERT INTO employee VALUES(100, 'David', 'Wallace', '1967-11-17', 'M', 250000, NULL, NULL);
INSERT INTO branch VALUES(1, 'Corporate', 100, '2006-02-09');
각각의 Table에 VALUES()안에 각 Feild에 해당되는 값을 넣어서 새로운 데이터를 추가할 수 있다. 앞서, employee Table의 super_id Feild를 외래키로 설정하고, employee Table의 emp_id Feild를 참조하도록 하였지만 데이터를 추가할 때 NULL로 설정 하였음을 알 수 있다. 외래키의 경우 기본 키와 달리 NULL이 들어갈 수 있으며, 만약 값이 들어간다면 참조하는 값 중 하나로 설정되야 함을 의미한다.
- UPDATE SQL
Table에 있는 데이터를 수정할 때는 UPDATE SQL을 사용해야 한다.
UPDATE employee SET branch_id = 1 WHERE emp_id = 100;
UPDATE 뒤에오는 Table에서 WHERE 뒤에오는 조건을 만족하는 데이터에 대하여 SER 뒤에오는 것을 수행한다. 위의 경우 employee Table의 emp_id Feild가 100인 데이터에 대하여 branch_id Feild를 1로 설정하라는 의미이다.
앞서 INSERT로 추가한 데이터의 경우 emp_id Feild가 100인데, branch_id Feild를 NULL로 입력하였다. 따라서 해당 UPDATE SQL로 인하여 branch_id Field의 값이 1로 변경됨을 예측할 수 있다.

실제로 적절히 Table의 값이 변경되었음을 확인할 수 있다.
'Database' 카테고리의 다른 글
| [ DB ] 데이터베이스...6(SQL...2) (4) | 2024.10.12 |
|---|---|
| [ DB ] 데이터베이스...5(SQL...1) (2) | 2024.10.11 |
| [ DB ] 데이터베이스...4(MySQL) - 작성중 (0) | 2024.10.11 |
| [ DB ] 데이터베이스...3(EER Diagram) (0) | 2024.09.30 |
| [ DB ] 데이터베이스...2(ER Diagram) (0) | 2024.09.29 |


