

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Python
- dfs
- 그래프 이론
- AlexNet
- MySQL
- BFS
- eecs 498
- CNN
- opencv
- two-stage detector
- machine learning
- Reinforcement Learning
- 강화학습
- real-time object detection
- ubuntu
- deep learning
- C++
- 머신러닝
- One-Stage Detector
- Mask Processing
- DP
- 백준
- r-cnn
- MinHeap
- 딥러닝
- dynamic programming
- YoLO
- object detection
- image processing
- LSTM
- Today
- Total
JINWOOJUNG
[ 컴퓨터 비전 ] Ch5. Deep Learning...1 본문
본 컴퓨터 비전 개념과 기법들에 대한 공부를 진행하면서 배운 내용들을 중심으로 정리한 포스팅입니다.
책은 Computer Vision: Algorithms and Applications를 기반으로 공부하였습니다.
또한, 인하대학교 박인규 교수님의 컴퓨터 비전 과목을 기반으로 제작된 포스팅입니다.
Intro
정통적인 Computer Vision은 SIFT와 같이 사람이 제공(제안)하는 Algorithm을 기반으로 특징을 추출하고, Image Stitching/Object Detection과 같은 Task를 사람이 제공(제안)하는 Algorithm을 기반으로 수행하였다.
Machine Learning으로 넘어가면서, 특징 추출과정에서 사람이 영향을 주는 것은 동일하다. 하지만, SVM/Linear Classifier과 같이 Model은 정해주되, Model의 Parameter는 Data로부터 학습하는 것이 Machine Learning이다. 따라서 Hand-crafted Features에 따라서 Machine Learning Model의 성능이 달라진다.
Deep Learning은 Data로 부터 Model이 직접 결정한 Feature를 기반으로 Model이 Data로부터 Parameter를 학습하는 것을 의미한다.

Machine Learning
머신러닝은 Large Dataset으로부터 Model을 학습시키고, 그 과정에서 Model Parameter가 결정된다. 그리고 새로운 데이터로부터 해당 모델의 성능을 평가하는 과정으로 이루어진다.
이러한 학습은 크게 Supervised Learning과 Unsupervised Learning으로 나눌 수 있다.
Supervised Learning
Supervised Learning은 지도학습으로, Labed Data 즉, Image와 Label(Class)를 모두 포함하고 있는 Training Data로 학습하는 학습 방법이다.
지도 학습을 기반으로 수행할 수 있는 여러 Task가 존재한다.
- Image Classification
- Image가 속하는 Discrete Category(Class)를 예측
- Image Regression
- Image에 해당하는 실수값을 가지는 물리적 Value를 추정
- Image Captioning
- 질문은 정해져있고, 해당 영상에 대하여 질문에 대답(설명)하는 Task
Unsupervised Learning
지도학습과 달리, 비지도 학습은 Image만 존재하고, Label이 없는 Training Data를 기반으로 학습하는 학습 방법이다. Label이 없기에 정답을 모르므로, 모델 스스로 내제적 성질(구조)를 파악하여 학습한다.
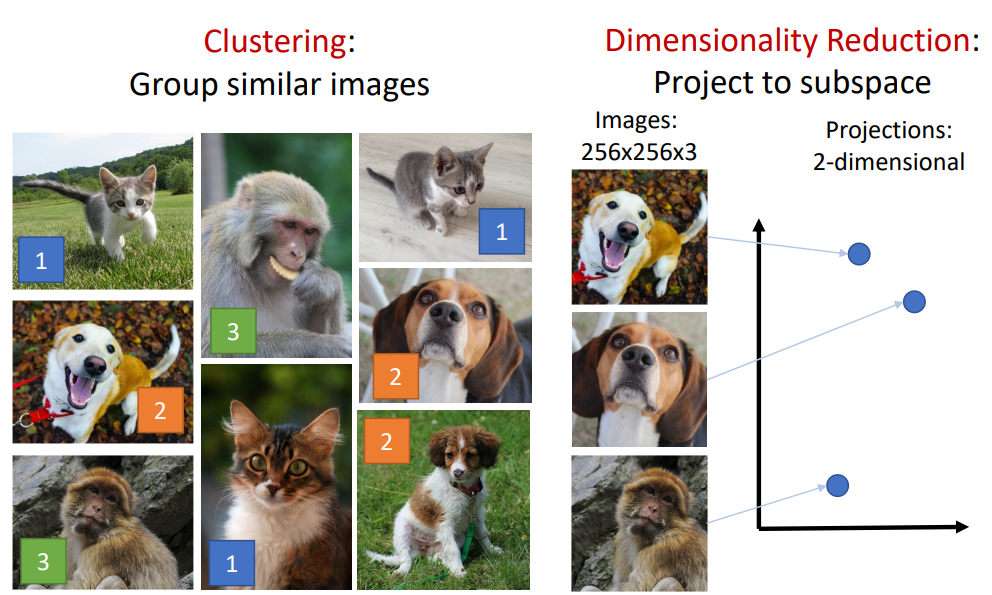
비지도 학습의 대표적인 Task로는 Clustering과 Dimensionality Reduction을 들 수 있다.
Clustering의 경우 Label이 없는 데이터로부터 모델이 스스로 학습한 내제적 성질을 기반으로 유사한 Data를 군집화 하는 과정이다.
Dimensionality Reduction은 차원 축소의 일환으로, 데이터를 단순화하면서도 중요한 정보를 최대한 보존하는 작업이다. 예를 들어, 데이터가 3차원(RGB 이미지)으로 주어졌을 때, 주요 분석 목적이 색상 정보가 아니라 구조적 특징에 초점이 맞춰져 있다면 Grayscale로 변환하여 차원을 줄일 수 있다. 이와 같이 차원을 축소함으로써 노이즈를 줄이고, 데이터 분석 및 머신러닝 모델의 효율성을 높이는 데 기여한다. 대표적인 차원 축소 방법으로는 PCA(Principal Component Analysis)와 t-SNE 등이 있으며, 이는 데이터의 표현력을 유지하거나 향상시키는 데 주로 사용된다.
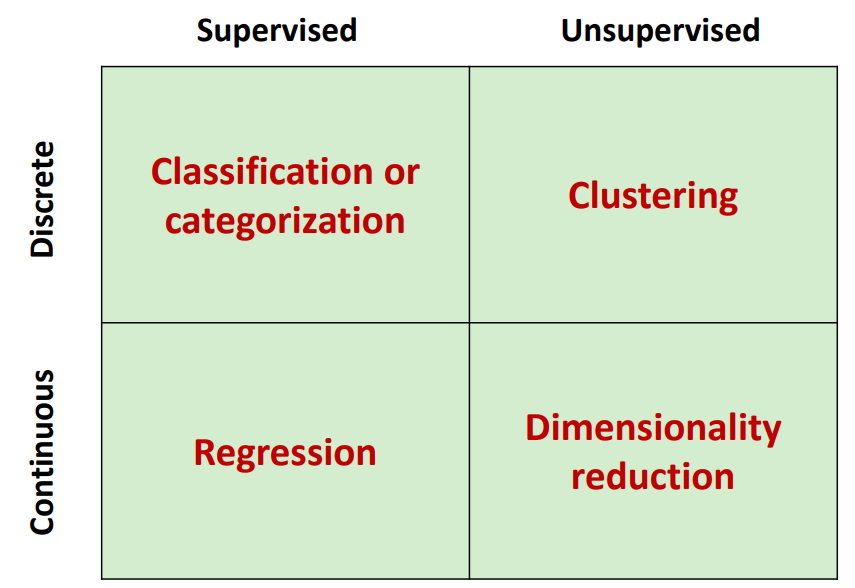
앞서 언급한 Machine Learning Task를 분류 해 보면 다음과 같다.
Biological Neural Network
사람의 뇌에 있는 뉴런은 다음과 같은 구조로 이루어져 있다. 그리고 뉴런과 뉴런이 연결된 Neural Network를 이루고 있다.
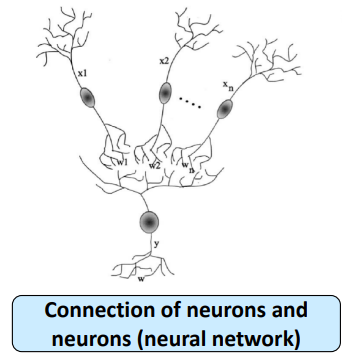
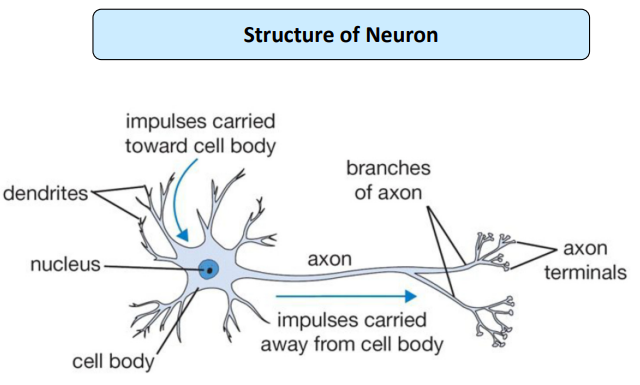
실제 뉴런 구조와 유사하게 인공적으로 만든 뉴런 신경망(Neural Network)가 바로 Perceptron이다.
Perceptron
Perceptron은 가장 간단한 신경망 구조를 의미한다. 가장 간단한 구조이기에 Single Neuron Model임을 확인할 수 있다.
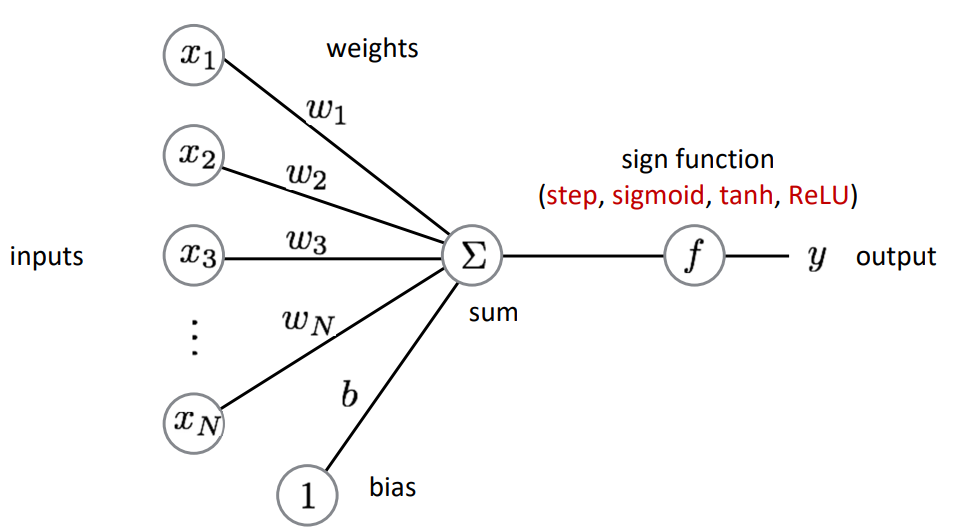
Input Vector(x1,x2,⋯,xN)로 들어온 Input은 하나의 Neuron으로 가중합 되어 들어온다.
b+x1w1+x2w2+⋯+xNwN=∑xiwi+b
이때, b는 bias를 의미한다.
이렇게 Neuron으로 들어온 가중합은 Activation Function을 거쳐 Output y를 도출하게 된다.
위 구조의 표현을 더욱 간단하게 하기 위해 bias를 xN=1,wN=b로 설정하여 하나의 Input Vector의 가중합으로 표현할 수 있고, 이를 Activation Function의 Input으로 표현할 수 있다.
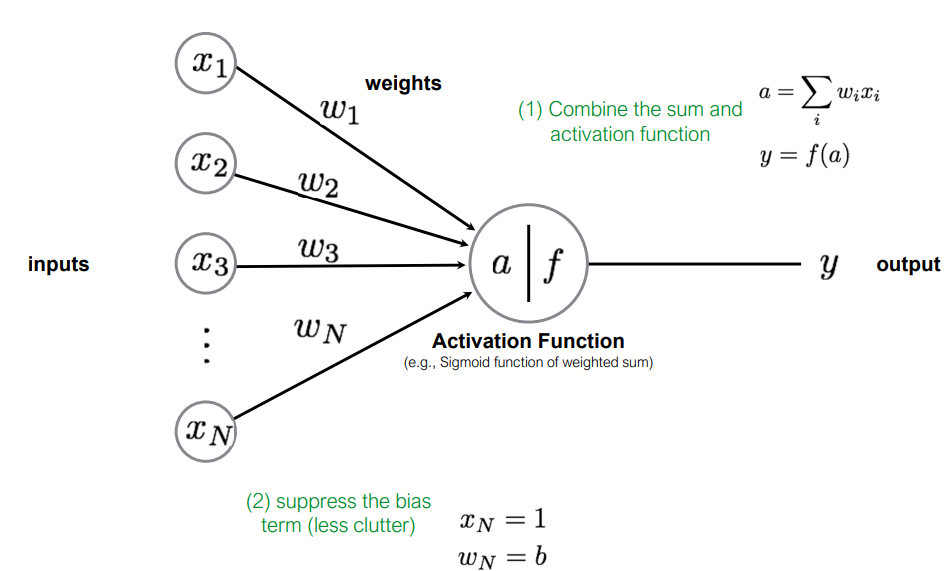
Model을 Linear Regression(선형 회귀)로 설정했다고 가정하면, Perceptron Function을 다음과 같이 Input Vector와 Weight Vector의 내적으로 표현할 수 있다. 그리고, 내적된 결과를 Activation Function의 Input으로 하여 해당 결과를 반환하면 Perceptron의 동작 과정을 표현할 수 있다.

Activation Function
활성화 함수는 입력 신호를 처리하고 출력 신호로 변환하는 함수입니다.
활성화 함수는 Sigmoid, ReLU 등 비선형 함수를 사용합니다. 만약 활성화 함수 f(x)가 선형 함수인 f(x)=cx를 사용한다고 하면, 신경망이 깊어짐에도 단순히 선형 변환의 조합으로 신경망을 표현할 수 있게 됩니다. 3층의 신경망이 존재한다고 하면, y(x)=h(h(h(x)))=c3x가 되는데, 이는 f(x)=c3x인 활성화 함수를 사용한 것과 동일하게 되므로 신경망을 깊게 쌓은 의미가 없게 됩니다. 즉, 활성화 함수를 통해 신경망이 비선형적인 데이터 분포를 학습하고, 복잡한 문제를 해결할 수 있도록 학습할 수 있습니다.
또한, Input의 범위는 (−∞ ∞)이지만, Output Layer는 Limitation이 존재한다. 만약 그렇지 않으면 Layer가 깊어질수록 발산하기 때문에, 활성화 함수를 통해 뉴런의 출력 값을 특정 범위로 제한하거나 변환하여 안정성을 보장한다.
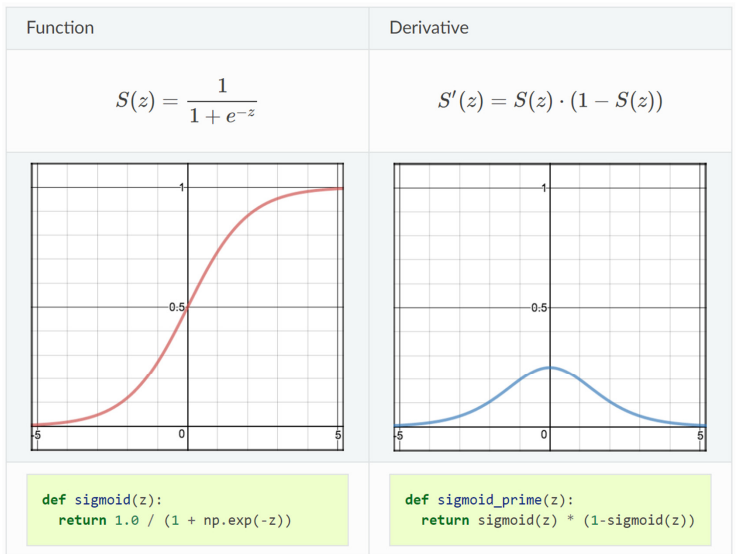
- Sigmoid
Sigmoid 함수는 아래와 같이 (0 1)의 Range를 가지며, Pre-activation Value가 커질수록 1에 수렴하는 경향을 보인다. 이때, Pre-activation Value는 Activation Function의 Input을 의미한다.
Sigmoind 함수는 Pre-activation Value이 무한대로 갈수록 Sigmoid의 Output이 차이가 없어져 Gradient가 작아지므로, 학습에 미치는 영향이 줄어든다.
또한, Sigmoid의 Derivative를 보면, 추가적인 미분 계산 없이, Sigmoid S(z)로 미분을 표현할 수 있다.
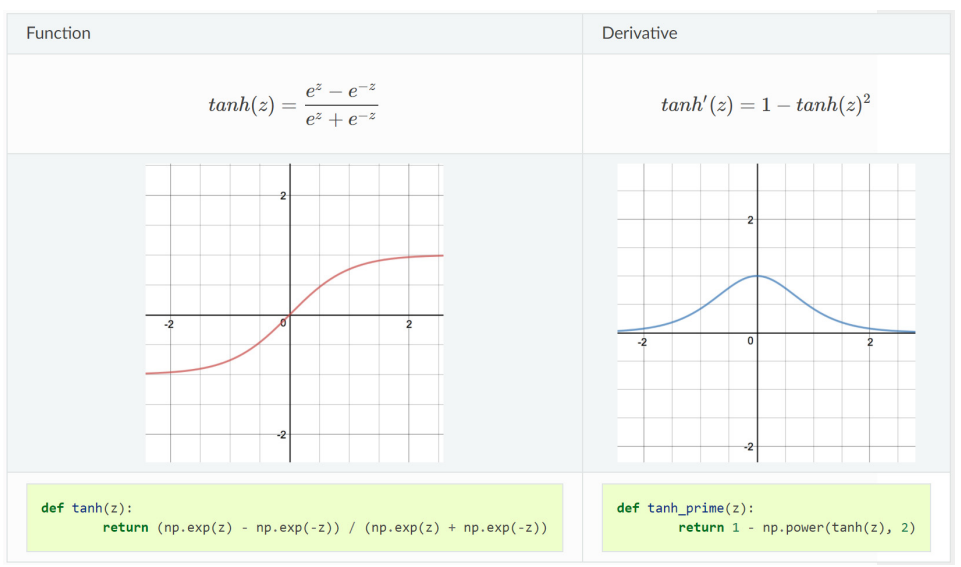
- tanh
tanh 함수는 Sigmoid Function과 유사하지만, (−1 1)의 Range를 가짐을 확인할 수 있다. 따라서 Sigmoid Function S(z)를 y축으로 0.5 줄이고, 2배를 하면 되므로 다음과 같이 표현할 수도 있다.
tanh(z)=2(S(z)−12
tanh Function의 Derivative를 살펴보면, Sigmoid Function보다 크다 즉, Gradient가 큼을 확인할 수 있다.
Artificial Neural Network(ANN)
인공신경망은 생물학적 신경망의 구조와 기능을 기반으로 한 모델로, 퍼셉트론들이 Layer로 구성되고, Layer간 연결을 통해 신호를 전달하며 문제를 해결하는 구조이다.
Multi-Layer Perceptron(MLP)
MLP는 입력층(Input Layer), 하나 이상의 은닉층(Fully Connected Layer), 출력층(Output Layer)로 구성된 ANN으로, Hidden Layer가 Fully Connected Layer로, 모든 노드가 연결된 구조이다.
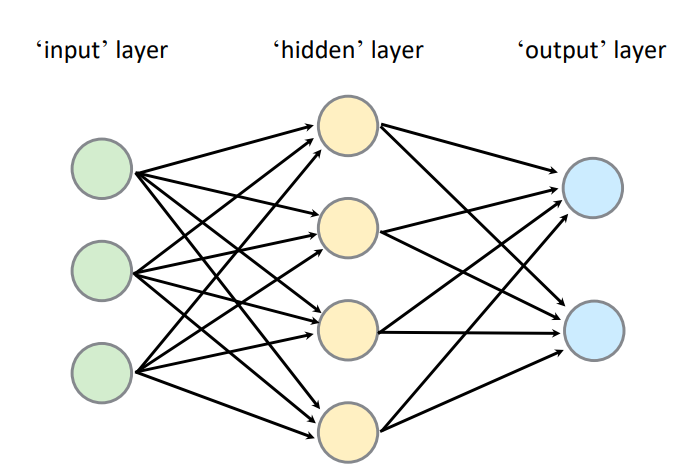
위와 같은 구조에서는, 총 6개의 Nodes(Neurons, Perceptron)이 존재하며, Fully Connected Layer이므로 3x4 + 4x5 = 20개의 Weights(Edges)가 존재한다. 또한, 각 Node 마다의 bias를 고려한다면 총 26개의 Learnable Parameters가 존재함을 확인할 수 있다.
MLP의 경우 2-3개의 Layer를 가질 때 성능이 가장 우수하며, DNN(Deep Neural Network)와 달리 깊어질수록 좋은 성능을 내는 것은 아니다. 이는 여러가지 이유가 있을 수 있는데,
- Layer가 깊어질수록 Fully Connected Layer이기에 학습해야 할 Parameter가 기하급수적으로 증가
- Fully Connected Layer이기 때문에, 지역적인 구조를 학습하지 않고 항상 전역적(모든 입력 뉴런과 연결된 가중치)를 고려함
- Sigmoid, Tanh를 사용하는 경우 Bagpropagation 과정에서 0~1사이의 작은 Gradient가 계속 곱해지면 매우 작아져 Gradient Vanishing Problem이 발생
- Gradient가 0으로 수렴
Training Perceptron
Perceptron의 학습 과정을 살펴보기 위해 가장 간단한 Perceptron을 가정하자. 각 Layer에는 Single Perceptron만 존재하며, Activation Function이 따로 없는 구조이다.
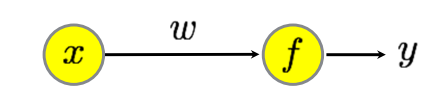
(x1,y1),⋯,(xN,yN) 총 N개의 Training Data가 있다고 할 때, Perceptron은 다음과 같이 표현할 수 있다.
ˆy=wx
그렇다면, Perceptron을 학습시킨다는 것은, Perceptron Output $\hat{y}이Data의TrueLabely$와 가까워지도록 Weight w를 변형시키는 것을 의미한다. 그리고 가까워진다는 것은 결국 ˆy와 y의 차이가 0에 수렴함을 의미한다.
따라서 우리는 학습하는 과정에서 Model의 성능 즉, w가 적절한지 판단하는 기준으로 Loss Function을 정의하는데, 일반적으로 L1 Loss, L2 Loss가 사용된다.
L1 Loss는 Sum of Absolute Difference(SAD)로, Error(ˆy−y)의 절댓값 합을 의미하며, L2 Loss는 Sum of Squared Difference(SSD)로, Error(ˆy−y)의 제곱합을 의미한다.
따라서 학습의 목적은 Loss Function이 줄어드는 방향으로 학습해야 한다.
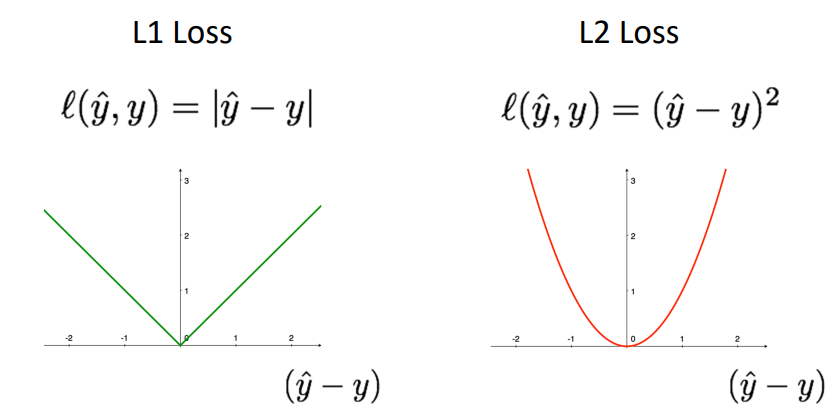
ˆy=wx라고 했을 때, 모든 Training Data에 대하여 w를 Update하는데, (yn−ˆy)xi인 방향으로 w가 Update되어야 Loss Function이 최소가 되는 방향이라고 할 수 있다.

그럼 그 방향이란 것은 어떻게 정의될까?
Gradient
우리는 Gradient라는 개념을 기울기라고 사용하고 있다. 어떤 함수의 Gradient는 미분값(기울기)이며, 해당 값이 클수록 더 가파름을 의미하고, 이는 꼭데기를 향하는 방향이다.
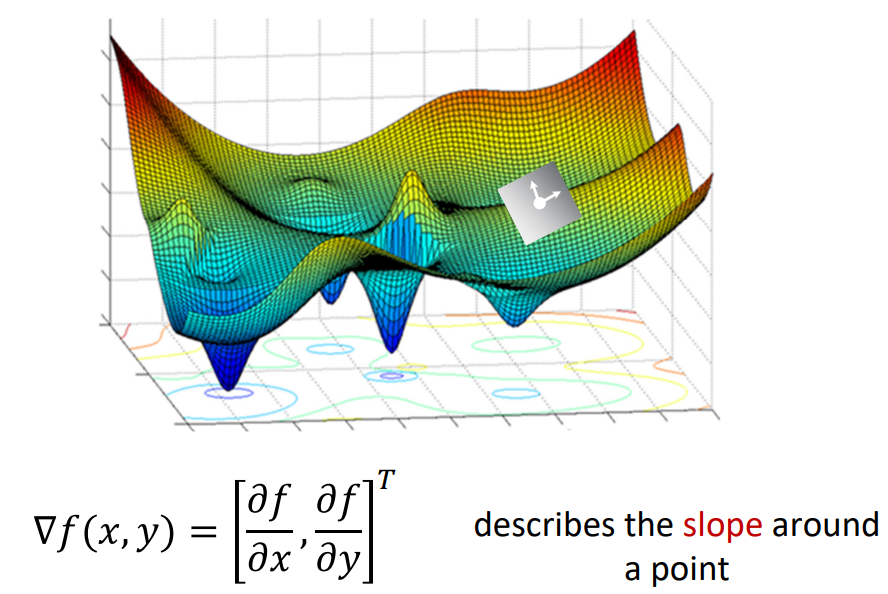
이때, 우리의 함수는 Loss Function이므로, Loss Function이 작아지는 것이 목적이기에 Gradient가 줄어드는 방향이 목적이 된다. 따라서 Weight w가 Update되는 과정은 다음과 같고, 이를 Gradient Descent라 한다.
w=w−▽w
다시 돌아와서, ˆy=wx이고, 우리의 학습은 Gradient Descent임을 확인하였다.
Loss Function L은 L2 Loss Function이라고 했을 때, Gradient를 계산 해 보면 다음과 같다.
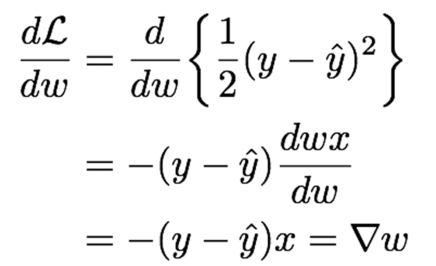
이때, Chain Rule이 사용된다.
dLdw=dLdˆy⋅dˆydw
그리고 ˆy=wx이므로, Loss Function의 미분은 −(y−ˆy)x가 되는 것이다.
Gradient Descent를 위해 Weight w의 Update는 w=w−▽w이므로, w=w+(y−ˆy)x가 된다.
정리 해 보면 다음과 같다.
Training Data xi,yi에 대하여 예측을 수행한 뒤 Loss를 계산한다. 이후 Back Propagation 과정에서 Loss의 미분을 계산하고, Gradient Descent로 Weight w를 Update하면서 학습하게 된다.

'2024 > Study' 카테고리의 다른 글
| [ 컴퓨터 비전 ] Ch5. Deep Learning...3 (0) | 2024.11.26 |
|---|---|
| [ 컴퓨터 비전 ] Ch5. Deep Learning...2 (0) | 2024.11.23 |
| [ 영상 처리 ] Ch11. Computational Photography(2) (0) | 2024.06.08 |
| [ 영상 처리 ] Ch11. Computational Photography(1) (2) | 2024.06.05 |
| [ GRAPH ] Topological Sorting (0) | 2024.06.02 |



