
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- machine learning
- deep learning
- ubuntu
- eecs 498
- DP
- Mask Processing
- opencv
- Python
- 딥러닝
- BFS
- MySQL
- AlexNet
- MinHeap
- image processing
- two-stage detector
- 백준
- 강화학습
- 머신러닝
- One-Stage Detector
- r-cnn
- C++
- real-time object detection
- CNN
- LSTM
- 그래프 이론
- dynamic programming
- YoLO
- Reinforcement Learning
- dfs
- NLP
- Today
- Total
JINWOOJUNG
[ 컴퓨터 비전 ] Ch5. Deep Learning...7 본문
본 컴퓨터 비전 개념과 기법들에 대한 공부를 진행하면서 배운 내용들을 중심으로 정리한 포스팅입니다.
책은 Computer Vision: Algorithms and Applications를 기반으로 공부하였습니다.
또한, 인하대학교 박인규 교수님의 컴퓨터 비전 과목을 기반으로 제작된 포스팅입니다.
https://jinwoo-jung.tistory.com/116
[ 컴퓨터 비전 ] Ch5. Deep Learning...6
본 컴퓨터 비전 개념과 기법들에 대한 공부를 진행하면서 배운 내용들을 중심으로 정리한 포스팅입니다. 책은 Computer Vision: Algorithms and Applications를 기반으로 공부하였습니다.또한, 인하대학교
jinwoo-jung.com
Deep Learning Object Detection Methods
Object Detection Task를 위한 Deep Learning의 발전은 아래와 같다. 특히 YOLO 계열과 R-CNN 계열은 논문을 직접 살펴볼 필요가 있다고 생각한다.

몇가지 Detector만 살펴보자면, 먼저 VJ Detector 이다. VJ Detector는 Face Detection을 주 목적으로 하는 Detector로, 가장 큰 특징이 Harr like feature, AdaBoost이다. Harr like feature는 얼굴 검출을 위해 얼굴에 나타나는 명암을 검출하는 Filter로 Response가 높은 Harr like feature를 검출하는 것이다. 또한, AdaBoost는 weak classifier의 연속적인 조합으로 복잡한 문제를 해결하는 방법이다.
이러한 Detector는 AlexNet이후 크게 One-stage Detector와 Two-stage Detector로 나뉘었다.
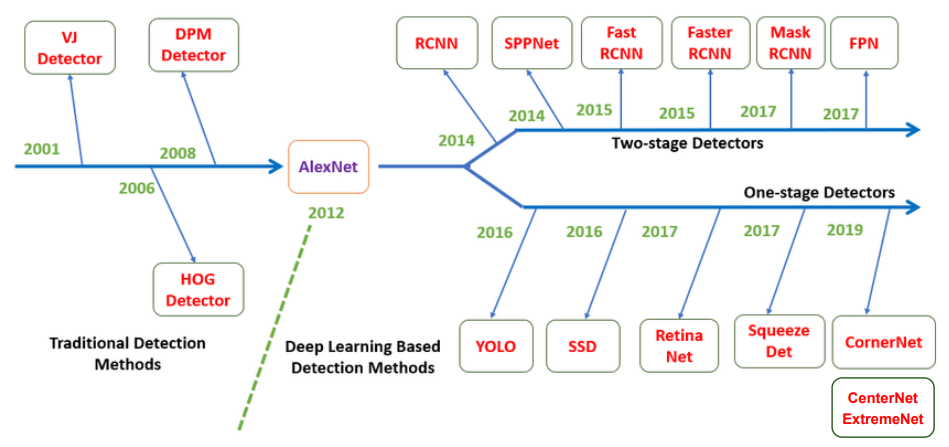
One(Single)-stage Detector는 End to End로 하나의 Network에서 Feature Extraction과 각각의 Task가 이루어지는 구조를 의미한다. Object Detection의 One-stage Detector는 Feature를 검출하는 Backbone을 거쳐 각각의 Task를 수행하는 Head로 나뉘어 Calssification과 Localization을 수행한다. 이는 매우 빠른 속도를 가지지만, FP(맞다고 잘못 판단한 경우)가 많다.
Two-stage Detector의 경우Feature Extraction을 거친 뒤, 추출한 Feature Vector를 바탕으로 Object가 있을 법한 Object Proposal(Region Proposal)를 검출한다. 이후 Region Proposal을 기반으로 Classification, Localization을 수행한다. 이는 학습에 더 어렵고 느리지만, 더 정확한 검출 결과를 가진다.

You Only Look Once(YOLO)
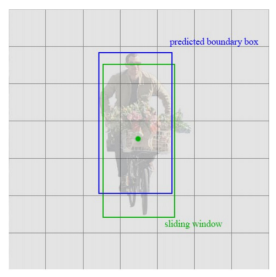
YOLO는 Object Detection의 근본적인 문제인 Full Search로 인한 높은 Cost와 시간이 오래 걸리는 문제를 Singe-stage를 통해 해결하면서 높은 성능은 유지한 Object Detector이다.
기존 Sliding Window 방식을 대신하여 YOLO는 이미지를 Grid로 나누고, 각 Grid Cell에서 특정 위치에 객체가 있는지 확인한다. Grid의 Feature Vector 정보를 바탕으로 객체가 있을 가능성이 높은 경우, 미리 정의된 크기와 비율의 Anchor Box를 K개 생성한다. Anchor Box는 초기 Bounding Box (BBox) 추정 위치를 제공하며, 이후 Regression을 통해 정확한 객체 위치로 조정된다. 동시에 각 Grid는 Objectness Score와 함께 Class Probabilities를 계산한다.
Training 과정에서는 Ground Truth BBox의 중심이 속한 Grid가 해당 BBox를 담당하게 된다. 이때, Grid Cell 내 Anchor Box 중 IoU가 가장 높은 Anchor Box가 특정 Ground Truth BBox에 할당되며, 해당 Anchor Box는 Regression 및 Classification을 통해 학습된다.
테스트 과정에서는 예측된 BBox 중 NMS를 통해 IoU가 높은 중복된 BBox를 제거하고, Confidence Score가 가장 높은 하나를 선택한다. 이를 통해 최종적으로 각 객체에 대해 최적의 BBox, Class, Score가 반환된다.

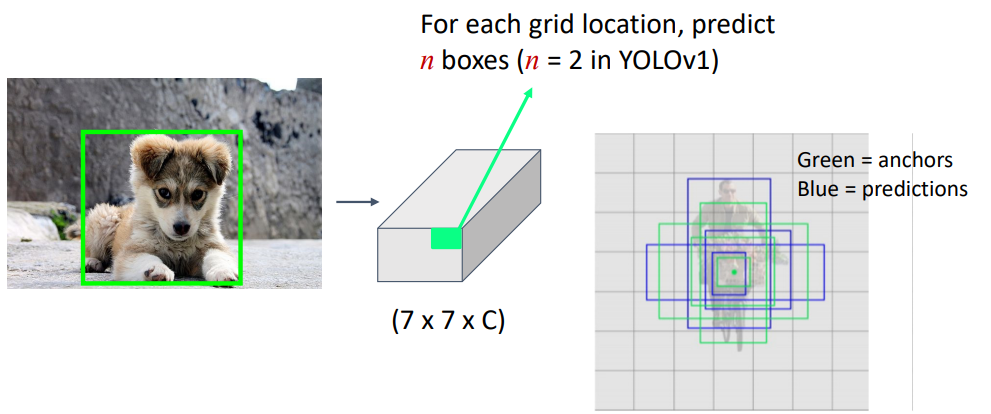
조금 더 살펴보면, 입력 영상에 대하여 7x7의 Grid를 생성한 뒤, 예측해야 할 클래스 개수 $C$의 Depth를 가지는 Tensor를 생성합니다. 이때, 각 Grid에 대하여 $n$개의 Anchor Box를 예측하게 됩니다.
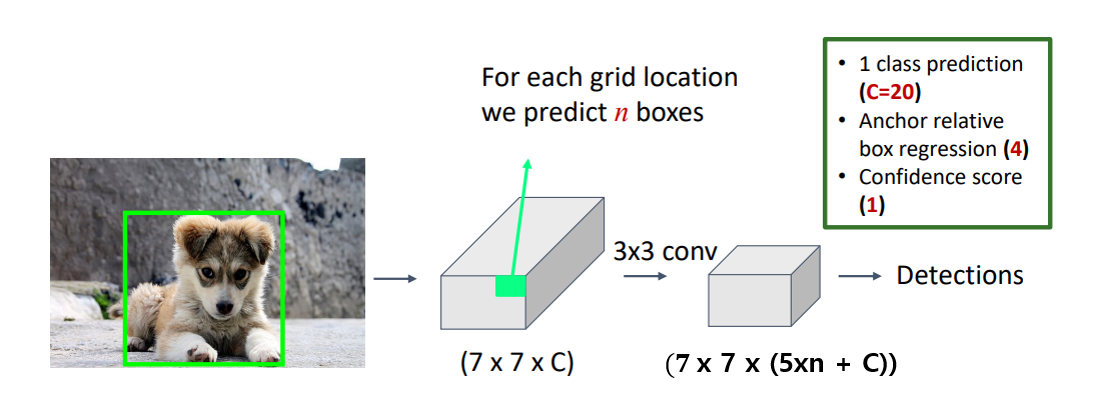
YOLO는 각 Anchor Box에 대해 Box Regression (x, y, w, h)와 Confidence Score를 계산하며, $C$개의 클래스에 대해 Class Probabilities를 계산한다. 따라서, YOLO의 출력 텐서는 7x7x(5n + C) 차원을 가지게 됩니다. 이는 7x7 Grid에 대해 각 Cell에서 Anchor Box의 개수 $n$과 클래스 수 $C$를 기반으로 예측값을 포함한 구조를 나타낸다. 결과적으로, YOLO는 Object Detection 문제를 Regression 문제로 해결하고 있음을 확인할 수 있다.
SSD(Single Shot Multibox Detector)
앞선 과정에서는 7x7 Grid의 각 Grid에서 Multi Object가 존재하는 경우에 대한 처리가 불가능하다. 따라서 SSD는 Multi Scale에서의 Object Detection이 가능하도록 차원을 축소시켜 가면서 검출한 결과를 반영하게 된다.
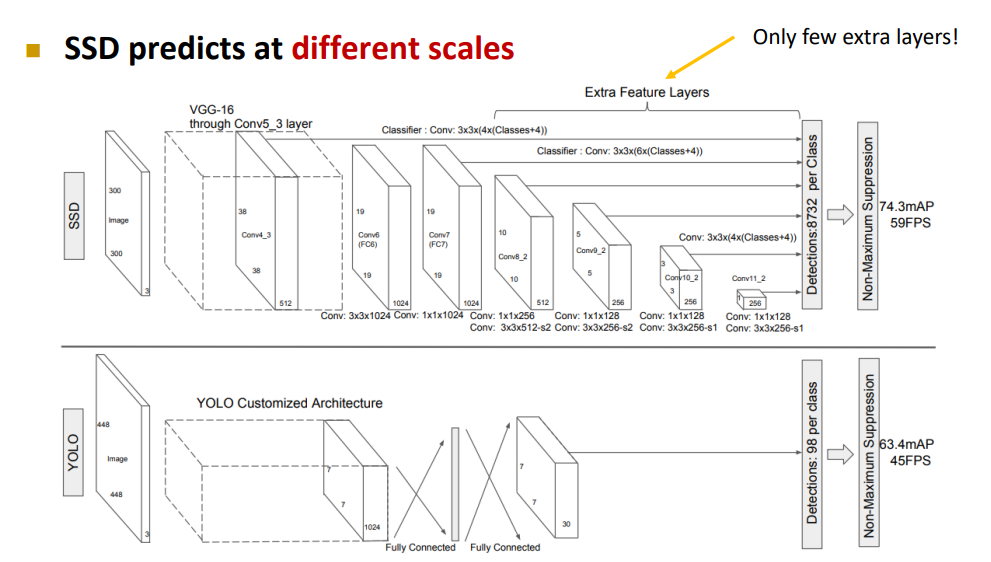
YOLOv2
YOLOv2에서는 Batch Normalization을 수행 하였으며, Grid의 차원을 늘리고, 입력 영상의 Resolution을 키웠다. 또한, Anchor Box의 개수를 9개로 확장하였다. 수행 결과(mAP) 및 속도(FPS) 모두 YOLO보다 우월한 성능을 확인할 수 있다.

'2024 > Study' 카테고리의 다른 글
| [ 컴퓨터 비전 ] Ch5. Deep Learning...6 (0) | 2024.12.03 |
|---|---|
| [ 컴퓨터 비전 ] Ch5. Deep Learning...5 (0) | 2024.12.02 |
| [ 컴퓨터 비전 ] Ch5. Deep Learning...4 (0) | 2024.11.26 |
| [ 컴퓨터 비전 ] Ch5. Deep Learning...3 (0) | 2024.11.26 |
| [ 컴퓨터 비전 ] Ch5. Deep Learning...2 (0) | 2024.11.23 |



