
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 강화학습
- r-cnn
- 머신러닝
- dfs
- MinHeap
- Mask Processing
- image processing
- two-stage detector
- AlexNet
- dynamic programming
- MySQL
- BFS
- C++
- NLP
- machine learning
- eecs 498
- 백준
- Python
- opencv
- ubuntu
- 딥러닝
- CNN
- DP
- LSTM
- Reinforcement Learning
- One-Stage Detector
- real-time object detection
- YoLO
- deep learning
- 그래프 이론
- Today
- Total
JINWOOJUNG
K-armed Bandit(1) 본문
본 게시글은 인하대학교 유상조 교수님의 Reinforcement Learning Tutorial Seminar
수강 후 정리를 위한 포스팅입니다.
모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다.
Before This Episode
https://jinwoo-jung.tistory.com/7
Reinforcement Learning
본 게시글은 인하대학교 유상조 교수님의 Reinforcement Learning Tutorial Seminar 수강 후 정리를 위한 포스팅입니다. 모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다. Reinforcement Learn
jinwoo-jung.tistory.com
K-armed Bandit
강화학습 알고리즘의 알 종류인 K-armed bandit에 대하여 알아보자.

K-armed Bandit는 k 개의 machine을 당기는 action을 통해 total reward를 maximize하는 problem이다.
이때, 각각의 machine은 알 수 없는 stationary probability distribution으로부터 서로다른 reward를 return 한다.
각 action의 reward 즉, 각 machine을 선택했을 때 return 되는 값은 true mean이 q∗(a) 인 PDF(Probablity density function)을 가지고 있으며 Agent는 이를 알 수 없다.
q∗(a)=E[Rt|At=a]
true mean을 수식적으로 해석 해 보면 K개 중 특정 a를 선택했을 때(At) Rt의 평균값으로 해석할 수 있다.
실제로 Agent는 이를 모르기에 시도해봄으로써 추정할 수 있는데, 이를 t step에서의 Sample Average(Sample Avg)(Qt(a))로 표현한다.
여기서 Agent는 강화학습 모델로 정의할 수 있다. 강화학습 모델은 특정한 Action을 통해 Environment(machine)으로 부터 보상을 얻게 된다.
강화학습 모델의 학습 방법
해당 모델은 어떻게 학습할까?
- 각 machine 마다 특정 횟수 시도 후 reward의 평균 계산
현재 각 machine's reward의 평균(true mean)을 모르기 때문에, 각 machine 마다 특정 횟수를 반복하여 Sample Avg를 구한 후 가장 높은 machine을 계속해서 당길 수 있다.이를 greedy action이라 한다.
At=argmaxaQt(a)
이러한 방법을 Exploration 즉, agent가 미래에 더 나은 결정을 할 수 있는 것을 시도하는 것으로 Sample Avg를 기반으로 판단한다. 하지만 이는 random 성이 없고, true mean은 낮지만 운이 좋아서 Sample Avg가 높아서 잘못 선택될 수 있다.

위 그래프를 보면 알 수 있듯이 true mean은 Agent가 알 수 없다. 따라서 시도 횟수(N)이 적을 때는 PDF가 넓게 형성되어 있다. 하지만 시도 횟수가 늘어날수록, PDF는 true mean을 중심으로 좁게 PDF가 형성된다. 따라서 위 방법으로 강화학습이 진행되면 Sample Avg 의 신뢰성을 보장할 수 없다.
- 시도 횟수를 증가시켜 Sample Avg의 신뢰성을 보장하기
위에서 설명한 것 처럼 시도횟수가 증가 될 수록, Sample Avg는 true mean과 유사해진다. 하지만 trial에 따른 cost가 높아지기 때문에 비효율적이다.
Qt(a)≈q∗(a)=E[Rt|At=a]
- ε-greedy action selection
무조건 적으로 greedy action을 행하는 것은 부정확하다. 따라서 ε은 Exploration 즉, greedy action을 취하지 않고 random하게 선택하고, 1- ε은 Exploitation 즉, greedy action을 취하는 강화학습 방법이 있다.

실제로 ε가 0 즉, greedy action만 취했을 때 보다 훨씬 더 좋은 성능을 보임을 알 수 있다.
그렇다면 계산된 추정치(Sample Avg)는 시도 횟수(n)의 증가에 따라 어떻게 새롭게 추정될 수 있을까?
n번 trial 했을 때, Qn+1=1n∑ni=1Ri 로 계산할 수 있다. 이를 조금 더 풀어보면

다음과 같이 Qn+1(예측값)을 Qn,Rn을 이용하여 표현할 수 있다.
위와 같은 Sample Avg의 계산은 stationary bandit problems 즉, reward PDF가 시도횟수에 따라 변화하지 않는 문제에 대해서는 효과적이다. 하지만 대부분의 강화학습 문제는 non-stationary하다. 즉, 시간에 따라 PDF가 변하기 때문에 1n∑ni=1Ri는 i=1부터의 평균값이므로 Sample Avg를 예측하는데 부정적이다.
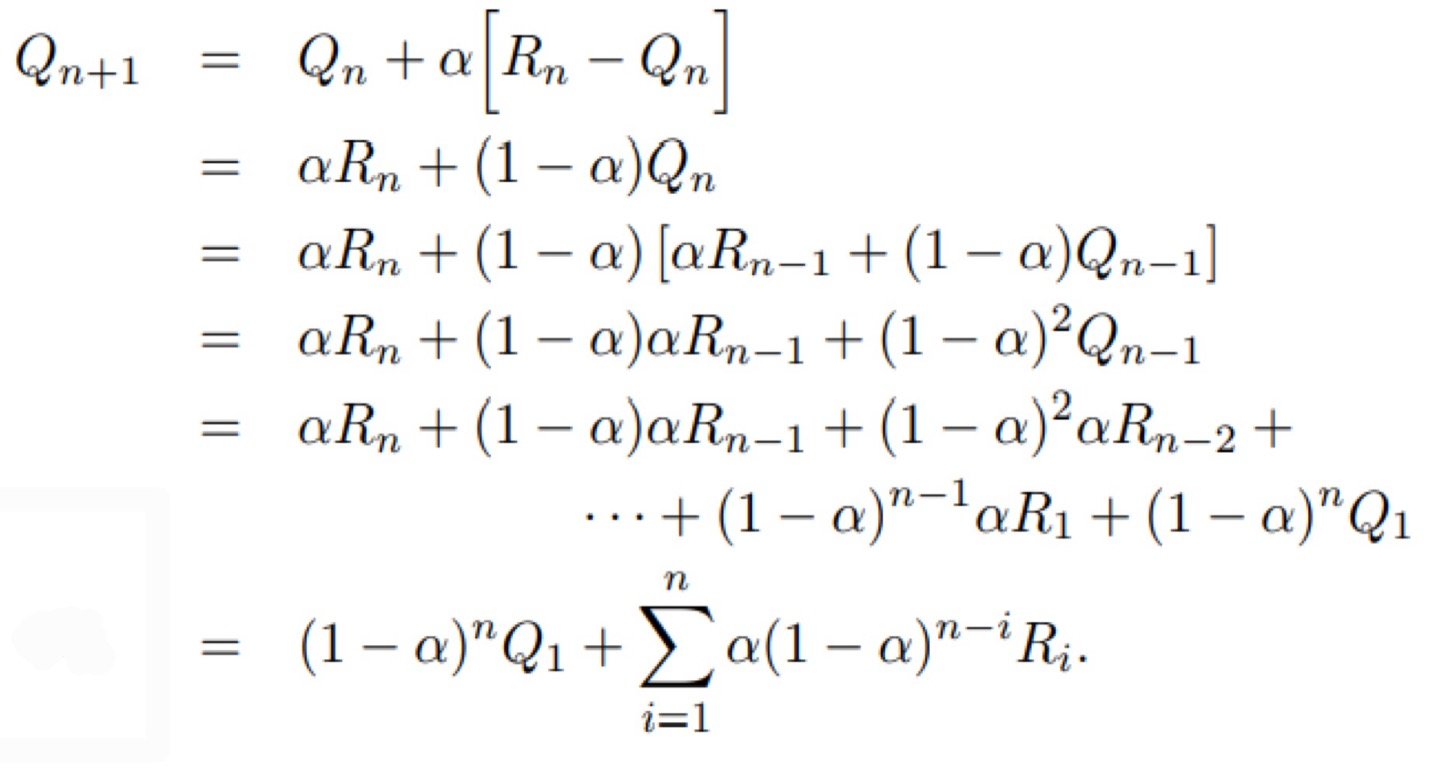
위 식을 조금 더 풀어보면 다음과 같이 표현할 수 있는데,
∑ni=1α(1−α)n−iRi=α(1−α)n−1R1+α(1−α)n−2R2+⋯+α(1−α)0Rn로 표현할 수 있다.
즉, 시도횟수가 증가할 수록 (1−α)가 1이되고 초기값의 경우 0으로 수렴하기 때문에 초기 Reward의 영향을 덜 받음을 알 수 있다. 따라서 1n을 변수(variable)이 아닌 상수(constant α)로 설정함으로써 해결할 수 있다. 위 식을 다시 써 보면 아래와 같다.
Qn+1≐Qn+α[Rn−Qn]
Sample Avg의 경우 바로 직전 time-step에서의 value(Qn)에 영향을 받기에 iterative하다고 표현한다.
이때, 수렴함을 판단하기 위한 조건(Convergence Conditions)가 존재한다.
∞∑n=1αn(a)=∞and∞∑n=1αn2<∞
따라서 α를 상수로 결정함으로써 Qt는 수렴하지 않지만, 이는 non-stationary environments이기에 계속 변하는 것이 당연하고 더 효과적이다.
stationary environment 에서는 step-size가 variable한 것이 더 좋다.
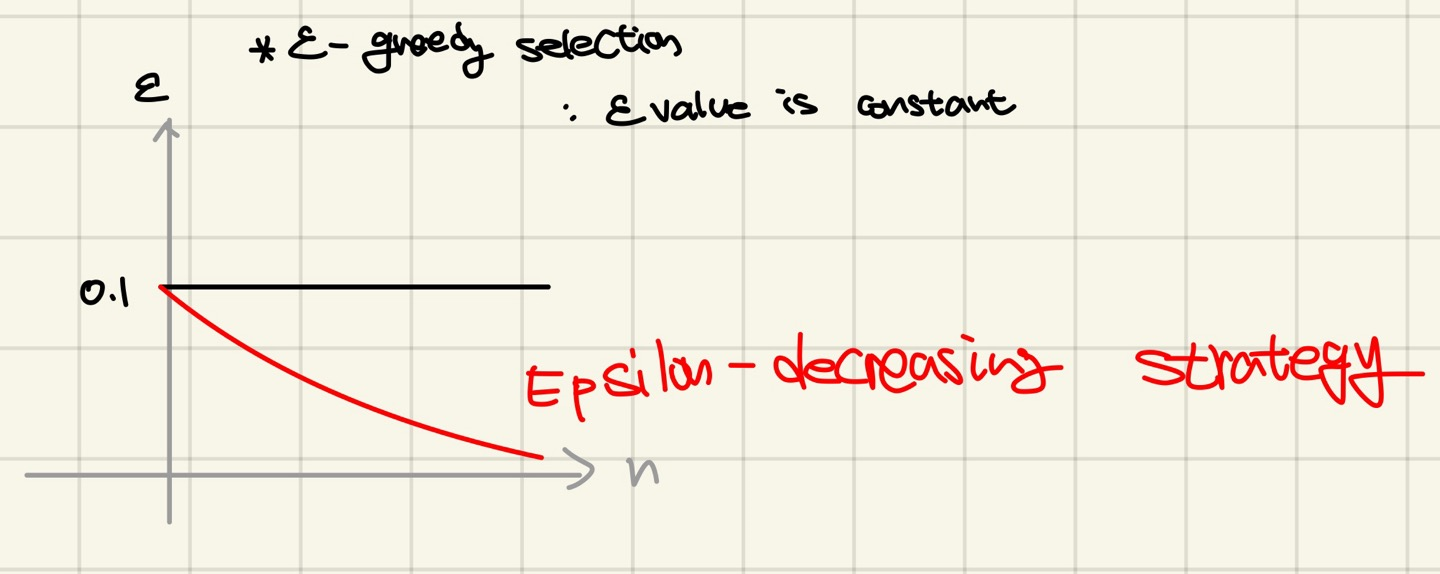
- ε-decreasing strategy
앞선 ε-greedy action의 경우 ε는 constant였다. 하지만 trail이 증가할수록 Sample Avg는 true mean에 가까워 지기 때문에 굳이 random selection을 할 필요가 없다. 따라서 ε value를 시간에 따라 감소시킴으로써 random selection의 비율을 줄이는 strategy가 등장하였다.
'Reinforcement Learning' 카테고리의 다른 글
| Bellman Optimality Equation (0) | 2023.12.30 |
|---|---|
| Markov Decision Process(MDP) (1) | 2023.12.29 |
| Markov Reward Process(MRP) (1) | 2023.12.29 |
| K-armed Bandit(2) (1) | 2023.12.28 |
| Reinforcement Learning (1) | 2023.12.27 |



