
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- NLP
- AlexNet
- 머신러닝
- ubuntu
- Mask Processing
- machine learning
- DP
- Reinforcement Learning
- eecs 498
- real-time object detection
- image processing
- 딥러닝
- MinHeap
- 백준
- One-Stage Detector
- LSTM
- two-stage detector
- MySQL
- opencv
- YoLO
- Python
- dfs
- 강화학습
- BFS
- 그래프 이론
- C++
- dynamic programming
- deep learning
- CNN
- r-cnn
- Today
- Total
JINWOOJUNG
Dynamic Programming 본문
본 게시글은 인하대학교 유상조 교수님의 Reinforcement Learning Tutorial Seminar
수강 후정리를 위한 포스팅입니다.
모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다.
Before This Episode
https://jinwoo-jung.tistory.com/16
Bellman Optimality Equation
본 게시글은 인하대학교 유상조 교수님의 Reinforcement Learning Tutorial Seminar 수강 후정리를 위한 포스팅입니다. 모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다. Before This Episode
jinwoo-jung.tistory.com
$S,A,P,R,\gamma$가 주어진 MDP에서 최적의 policy를 구하는 방법은 이전에 소개한 Bellman Optimality Equations로 계산할 수 있다.
$$v_*(s) = \underset{a}{max} \sum_{s',r}^{}p(s',r|s,a)[r+\gamma v_*(s')]$$
$$or$$
$$ q_*(s,a) = \sum_{s',r}^{}p(s',r|s,a)[r+\gamma \ \underset{a'}{max} \ q_*(s',a')]$$


State $s$에서의 최적의 state-value는 정해진 확률로 다음 state $s'$로 이동하고, 그때 받는 reward가 $r일 때,
$ r + \gamma v_*(s') $값이 최대가 되는 action에 의해 변화되는 $s'$에서의 state-value로 결정되며 이때의 policy가 최적의 policy임을 의미한다.
State $s$에서의 최적의 action-value 역시 action $a$를 했을 때, 정해진 확률로 변화되는 $s'$에서 선택 가능한 action $a'$중 action-value가 가장 큰 action으로 결정되며, 이때의 policy가 최적의 policy임을 의미한다.
하지만 optimal state-value, action-value 모두 미래의 값으로 정의되기에 현재 state에서는 알 수 없다.
따라서 Model-based setup 즉, 사전에 $<S,A,P,R,\gamma>$를 모두 알고있는 경우 우리는 state-values, action-values를 계산하여 최적의 값을 구할 수 있다.
이때, Policy Evalution과 Policy Improvement를 통해 최적의 Policy에 접근할 수 있다.
Policy Evaluation
Policy Evaluation는 임의의 policy $\pi$에 대하여 state-value function $v_{\pi}$를 계산하는 것이다.
$$v_{\pi}(s) =\sum_{a}^{} \pi(a|s) \sum_{s',r}^{}p(s',r|s,a)[r+\gamma v_*(s')]$$
선형적으로 $v_{\pi}$에 대한 계산이 가능하지만, 매우 복잡하기 때문에 iterative solution methods를 적용하여 해결하는 것이 Dynamic Programming이다.
Dynamic Programming
$v_{k+1}(s)$에서는 $v_{\pi}(s')$는 $k+1$의 상황에서 알지 못하는 미래의 값이기 때문에, 이를 iterative하게 해결하기 위해서 $v_k(s')$으로 바꿈으로써 해결할 수 있다.
$$v_{k+1}(s) =\sum_{a}^{} \pi(a|s) \sum_{s',r}^{}p(s',r|s,a)[r+\gamma v_k(s')]$$
이때, update하는 방법에는 두가지 방법이 있는데, 먼저 Synchronous(동기식)의 경우 $v_k(s), v_{k+1}(s)$ 두가지 값을 각각 다른 배열에 저장하여 모든 정보를 사용한다. Asynchronous(비동기식)의 경우 하나의 배열만 사용하는 in-place 방식으로, $v_{k+1}(s)$로의 update가 있으면 바로 이전 갚을 update함으로써 동기식 방법보다 더 빠른 속도로 수렴함을 알 수 있다.
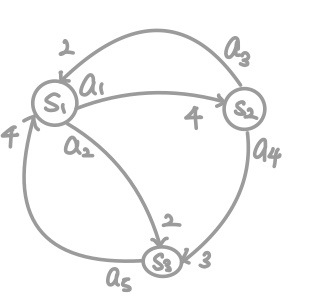
위의 MDP가 주어졌다는 가정 하에 Dynamic Programming을 통한 Policy Evaluation을 진행 해 보자.
Reward는 constant, State의 변화는 Diterministic, $\gamma$ = 1, $\pi$는 random selection한다고 가정 해 보자.
Iterative하게 계산하기 위해 초기값 $v_0(s_1)= v_0(s_2)= v_0(s_3) = 0$으로 가정한다.
$1_{st}$의 경우 $v_1(s_1)=0.5(4+v_0(s_2))+0.5(2+v_0(s_3))=3$이다. $v_1(s_2)=0.5(2+v_0(s_1))+0.5(3+v_0(s_3))=3$이다. 이 식을 잘 보면, 이미 $s_1$에 대한 state-value는 $v_1(s_1)$을 계산하는 과정에서 update 되었지만, 여전히 $v_0(s_1)$의 값을 이용하는 것을 확인할 수 있다. 즉, 동기식이다.
만약 비동기식으로 계산한다면, $v_1(s_2)=0.5(2+v_1(s_1))+0.5(3+v_0(s_3))=4$가 된다.
$v_1(s_3)$ 역시 비동기식으로 계산하면 $v_3(s_3) = 0.5(4+v_0(s_1)) = 2$이다.

Dynamic Programming을 통한 Policy Evaluation을 Sudo-Code로 나타내면 위와 같다. 초기 state-value를 설정하고 반복적으로 state-value를 update한 후 이전 값과의 차이가 가장 큰 값이 threshold보다 작을 때 까지 반복한다. 따라서 그때의 policy가 최적의 policy로 도출된다.
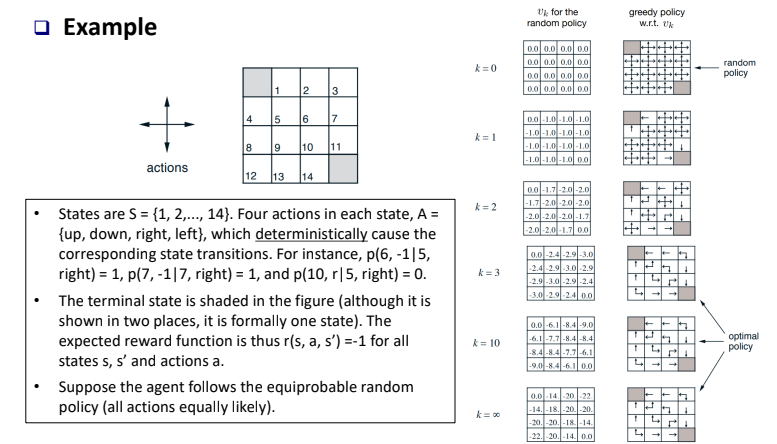
위 예시를 통해 더 정확히 이해할 수 있을 것이다. k가 무한대로 가면 각 state에서의 state-value는 최적의 값을 가지게 되고 그때의 policy가 optimal policy가 된다. 음수로 표현되는 것은 모든 state의 변화에 대한 reward가 -1이기 때문이다.
Policy Improvement
Policy Improvement는 Evaluation된 특정한 policy $\pi$에 대해서 $v_{pi}$를 알고 있을 때, greedy action을 통해 Policy Improvement가 가능하다.
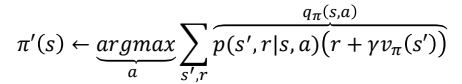
즉, evalution된 특정한 policy에 의해서 수행했을 때의 action-value들의 max가 되는 action을 선택하도록 policy를 바꿔준다. 따라서 Evaluation과 Improvement를 반복하면 최적의 Policy로 수렴함을 알 수 있다.
따라서 이를 Sudo-Code로 나타내면 아래와 같다.

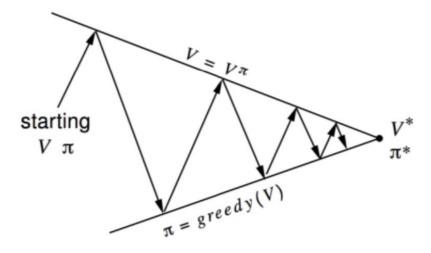
하지만 Policy Iteration의 경우 Evaluation 과정에서 반복 횟수가 많아지기에 이를 줄이고 Evaluation과 Improvement를 반복하게 하는 방법이 Value Iteration이다. 실제로 Value Iteration이 더 효과적임을 알 수 있다.

박스 친 부분을 보면 max action을 선택하여 Update를 한다는 의미는 최적의 policy가 되도록 policy가 변하기 때문에 Sudo-Code 상에서는 Policy에 대한 수식은 없지만, update 됨을 예측할 수 있다.
'Reinforcement Learning' 카테고리의 다른 글
| Temporal Difference Method (0) | 2024.01.19 |
|---|---|
| Monte Carlo Method (0) | 2024.01.19 |
| Bellman Optimality Equation (0) | 2023.12.30 |
| Markov Decision Process(MDP) (1) | 2023.12.29 |
| Markov Reward Process(MRP) (1) | 2023.12.29 |



